


Phishing
Le danger des emails de phishing
Dans cet article, vous apprendrez ce qu’est le phishing, comment il fonctionne et comment reconnaître les signes avant-coureurs d’une tentative de phishing. Nous explorerons différents types de phishing – comme le spear phishing, le smishing et le quishing – et vous proposerons des conseils pratiques sur la manière de vous protéger, vous et votre organisation, grâce à la sensibilisation, aux protocoles d’authentification et aux solutions avancées de sécurité des emails.
Définition du phishing
Le phishing est une manœuvre d’ingénierie sociale orchestrée par email. En tant que telle, il s’agit de la cybermenace la plus répandue. À la différence des cyberattaques qui ciblent les logiciels et les systèmes, le phishing ne demande que peu, voire pas d’expertise technique et permet donc aux cybercriminels d’accéder rapidement et facilement aux données les plus sensibles d’une entreprise.
Le phishing désigne un type de cybermenace dont le but est de mettre la main sur des informations sensibles par le biais d’une demande frauduleuse, le plus souvent par email. Les hackers contactent leur victime sous l’identité d’une marque établie ou d’une personne qu’elle connaît afin de faire croire à la légitimité de leur demande.
Les éléments de base du phishing
Tout d’abord, vous devez savoir ce qu’est l’ingénierie sociale. L’ingénierie sociale est en général une application des sciences sociales, mais elle est plus connue sous le nom de manipulation sociale ou d’escroquerie. Dans le cadre de l’ingénierie sociale, le délinquant utilise des connaissances psychologiques pour manipuler la victime afin qu’elle fasse ce qu’il veut qu’elle fasse. L’une des techniques consiste à se faire passer pour un collègue de la victime.
Par exemple, un collègue du service d’administration système peut envoyer un email frauduleux déguisé en email du responsable du service d’administration système. La victime est beaucoup plus disposée à faire ce que le pirate veut qu’elle fasse avec son ordinateur si elle pense que l’attaquant est un collègue. Une autre méthode consiste à préparer un email frauduleux, qui ressemble à un e-mail d’une entreprise de confiance, comme PayPal. Le pirate utilise cet email frauduleux pour piéger la victime et accéder à son compte PayPal.
Le phishing est une attaque par email frauduleux utilisée par les cybercriminels qui utilisent les techniques décrites ci-dessus. En général, il existe deux types d’attaques de phishing. Tout d’abord, la méthode la plus simple : le cybercriminel n’a pas besoin de beaucoup d’informations sur la victime. Il envoie autant d’emails de phishing que possible, à autant de destinataires que possible. Il part du principe que, dans une masse de personnes, quelqu’un réagira comme il veut qu’il réagisse. Plus le nombre d’emails envoyés est élevé, plus les chances augmentent.
L’autre variante des emails de phishing est appelée spear phishing. Les emails de spear phishing sont beaucoup plus personnalisés qu’un email de phishing normal. Le hacker tente d’attaquer une victime en particulier et la manipule avec des emails pour qu’elle lui transmette les données qu’il veut. Une variante de cette approche en deux étapes est appelée Barrel Phishing.
Comment fonctionne le phishing ?
Normalement, la cible du cybercriminel, également appelé hacker est en mesure d’obtenir des identifiants de connexion, principalement de services tels que PayPal ou similaires. Sinon, ils tentent généralement de voler des informations de carte de crédit. Pour atteindre cet objectif, ils utilisent des emails de phishing. Ces emails sont souvent structurés comme un email provenant du véritable service (Paypal, etc.), que les hackers utilisent pour inciter l’utilisateur à renoncer à ses identifiants de connexion.
Par exemple, ils créent un email qui ressemble à celui de PayPal. Dans cet email, il vous est souvent demandé de cliquer sur un lien pour saisir un nouveau mot de passe, parce que quelqu’un s’est connecté à votre compte ou quelque chose de similaire. Ils peuvent également utiliser des documents joints, auquel cas on vous demande d’ouvrir le fichier imitant quelque chose comme une facture, avec un logiciel malveillant à l’intérieur. Ce logiciel malveillant pourrait ensuite suivre tout ce que vous faites sur votre ordinateur. Cela peut sembler un peu paradoxal que les emails de phishing fonctionnent avec des emails qui devraient normalement vous avertir que quelqu’un essaie de se connecter à votre compte.
C’est à ce moment que l’aspect d’ingénierie sociale entre en jeu. Lorsque vous recevez un email vous informant que quelqu’un a tenté d’accéder à votre compte, vous êtes soumis à un stress psychologique. Imaginez que quelqu’un ait réussi à voler vos identifiants PayPal, il pourrait potentiellement accéder à tout votre argent. Les hackers utilisent ces pensées pour manipuler leurs victimes.
Types d’attaques de phishing
Spear phishing/Attaque BEC (Business Email Compromise)
Cette forme de phishing hautement ciblé usurpe l’identité d’un individu plutôt que d’une entreprise. Le plus souvent, il s’agit d’une personne connue de la victime. Si les attaques de spear phishing ne comportent généralement pas de lien malveillant ni de pièce jointe infectée, c’est parce que le piège se trouve dans le texte : des techniques d’ingénierie sociale et des recherches minutieuses permettent ainsi au hacker de tromper sa victime. La section suivante offre une définition plus complète du spear phishing et des différences avec un simple email de phishing.
Quishing
Également appelée QRishing ou phishing de QR code, cette technique dissimule des liens ou pièces jointes piégés dans les QR codes afin de contourner la détection des filtres d’email. Au-delà des techniques employées pour échapper à la détection, les attaques de quishing visent à obtenir les mêmes résultats que les menaces véhiculées par email de phishing.
Whaling
Ce type d’attaque de spear phishing prend pour cible des cadres supérieurs de l’entreprise afin de soutirer frauduleusement de l’argent, par exemple via un virement indu. Les attaques de whaling emploient les mêmes techniques d’ingénierie sociale que le spear phishing. La différence réside dans l’identité de la victime, plutôt que dans la méthode. D’après le National Cyber Security Centre (NCSC), le whaling cible principalement les institutions financières, les services de paiement et parfois les services de stockage dans le cloud, les services en ligne ou encore les entreprises d’e-commerce.
Clone phishing
Lors de cette attaque, les hackers copient un email légitime et en modifient le contenu pour le remplacer par des liens et pièces jointes de leur cru. L’email est ensuite renvoyé au destinataire initial, qui sera davantage susceptible de faire confiance au contenu jusqu’ici inoffensif d’un expéditeur connu.
Phishing sur les médias sociaux
L’usurpation sur les médias sociaux est un des types de phishing les plus répandus. Cette technique consiste à se faire passer pour une plateforme sociale et à envoyer de fausses notifications ou alertes aux utilisateurs. Les emails envoyés redirigent les utilisateurs vers des sites malveillants créés dans l’unique but de subtiliser leurs identifiants et de les utiliser pour se connecter à leurs comptes. Une fois le compte compromis, les hackers peuvent alors surveiller la victime, prendre le contrôle de son compte ou se faire passer pour le propriétaire du compte auprès de ses amis, sa famille et autres contacts.
Depuis 2020, Facebook est invariablement la première ou la deuxième marque la plus usurpée. La plateforme partage souvent le podium avec d’autres marques, comme Instagram et WhatsApp.
Vishing ou phishing vocal
Le vishing passe essentiellement par les communications téléphoniques. Le but est de pousser la victime à divulguer des informations sensibles au téléphone. Cette attaque peut mobiliser d’autres canaux de communication, par exemple l’email, ou bien se dérouler entièrement par téléphone. D’après la CISA, les tentatives de Vishing avancées exploitent bien souvent les solutions VoIP (Voice over Internet Protocol), qui permettent aux hackers de se faire passer pour des appelants légitimes.
Angler phishing
Ces attaques se déroulent sur les médias sociaux. Les hackers y créent de faux profils et se font passer pour des représentants du service client. Ils ciblent ensuite des utilisateurs de la plateforme qui se sont plaints de la marque. Prétextant un geste commercial, les hackers proposent un remboursement, un échange gratuit ou une offre alléchante par le biais d’un site malveillant et illégitime.
Phishing du moteur de recherche
Également connu sous le nom d’empoisonnement SEO, le phishing du moteur de recherche consiste à classer de façon frauduleuse un site malveillant au sommet des résultats de recherche. Cette opération procure une apparente légitimité au site, qui a pour objet de collecter des identifiants ou d’infecter des appareils.
Smishing ou phishing de SMS
Comme son nom l’indique, cette attaque est orchestrée par texto. Comme pour les emails de phishing, le smishing usurpe l’identité d’une marque bien établie, au nom de laquelle elle envoie un SMS à la victime. Ce SMS contient un lien malveillant, une demande d’information ou un numéro de téléphone contrôlé par le hacker en vue d’une tentative de Vishing. Les objectifs du smishing sont similaires à ceux d’un email de phishing.
Email phishing
Les emails sont le premier vecteur des tentatives de phishing. Les hackers se font passer pour une marque connue et envoient à leur victime un email contenant des liens malveillants ou des pièces jointes piégées. Ces attaques reposent sur des techniques d’ingénierie sociale qui incitent le destinataire à cliquer sur un lien de phishing ou à télécharger une pièce jointe compromise. L’intention des hackers est de collecter les identifiants de la victime, d’infecter l’appareil en y déposant un malware, d’exécuter une cyberattaque, etc.
Comment reconnaître un cas de phishing ?
Comment faire la différence entre un véritable email, qu’il est très important de recevoir, et un email qui n’est qu’un email de phishing ? Il existe quelques signes avant-coureurs qui permettent de reconnaître les emails de phishing et de les différencier des vrais emails. Grâce à ces astuces simples, vous pouvez souvent identifier les emails de phishing. Il est important de vous entraîner à vous poser la question suivante pour chaque email, en particulier ceux que vous n’attendiez pas : « s’agit-il d’un email de phishing ? »
Absence de formule d’appel personnelle
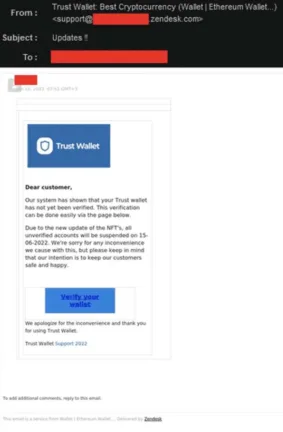
La première chose à vérifier est si l’email s’adresse à vous en utilisant votre nom. Souvent, les emails de phishing utilisent des expressions telles que « cher client » ou similaires. Les vraies entreprises utilisent souvent votre nom pour s’assurer que vous pouvez voir que leur email n’est pas un email de phishing et qu’il semble beaucoup plus sérieux.
The sender
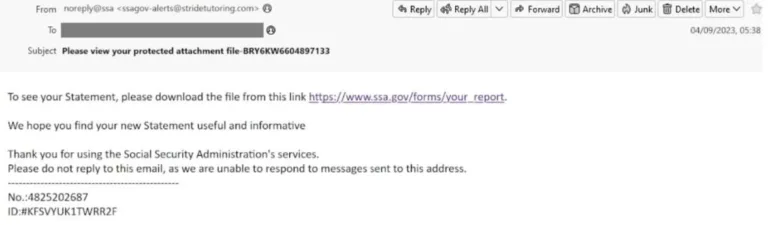
Pour vous protéger d’un email de phishing, vérifiez l’adresse email. Souvent, l’adresse email est très similaire à l’adresse email standard de la véritable entreprise, mais n’est pas la bonne adresse d’expéditeur. Par exemple, la véritable adresse email serait service@paypal.com et l’adresse email de phishing pourrait être service@paypai.com. Au premier coup d’œil, vous ne verrez pas de différence. Vous devez donc vous entraîner à examiner de plus près l’expéditeur des emails, afin de vous assurer qu’il ne s’agit pas d’un email de phishing.
En-tête de l’email
D’un autre côté, les bons cybercriminels sont capables de manipuler l’email de manière à ce qu’il semble que vous ayez reçu l’email de l’expéditeur auquel vous vous attendiez. Les personnes ayant de solides connaissances techniques ont la possibilité d’examiner l’en-tête de l’email pour trouver du code qui ne devrait pas s’y trouver ou qui est incorrect.
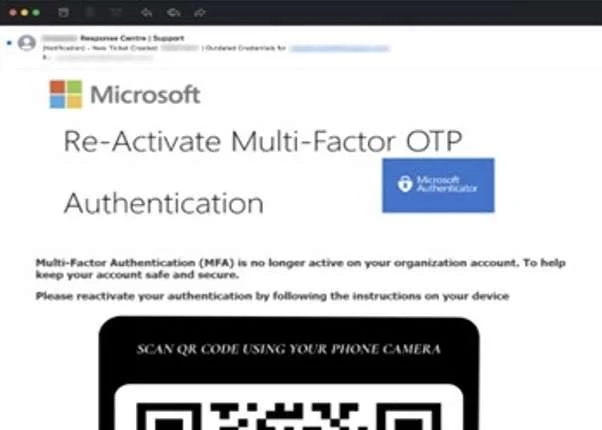
Fichiers joints trompeurs
Parfois, les hackers envoient des fichiers joints frauduleux. Cela se produit souvent lorsqu’ils ciblent des victimes qui travaillent dans des entreprises. Dans les entreprises, il est normal d’envoyer des emails avec des fichiers joints dans différents formats. Les employés ont l’habitude d’ouvrir tous les fichiers joints aux emails, sans y penser. Si le cybercriminel envoie un email avec un document intitulé « dernier rappel », l’employé peut alors être plus stressé.
Donc, sans même penser au phishing (hameçonnage), ouvrez-le et envoyez-le à la Comptabilité. Dans le fichier se cache un logiciel malveillant qui peut désormais lire tout ce qui est écrit sur l’ordinateur. La leçon à en tirer est de ne pas ouvrir les documents dont vous n’êtes pas sûr. Réfléchissez à la sincérité de l’email et n’ouvrez pas le fichier sans vraiment savoir si l’expéditeur est vérifié.

Alerte de sécurité
La victime reçoit une alerte de sécurité l’informant que son mot de passe a été compromis, qu’il y a une activité suspecte sur un compte ou qu’elle s’est récemment connectée à un compte à partir d’un appareil inconnu.
Par exemple, un utilisateur peut recevoir un email automatisé se faisant passer pour Netflix, l’une des marques de cloud les plus usurpées, l’informant d’une activité inhabituelle sur son compte. Si la victime clique sur le lien malveillant, elle est souvent dirigée vers une page de phishing conçue pour récupérer des identifiants permettant aux attaquants de pirater un compte Netflix.
Les comptes piratés de Netflix et de marques telles que Netflix, Hulu, DirectTV, Brazzers et autres sont couramment vendus sur le dark web.
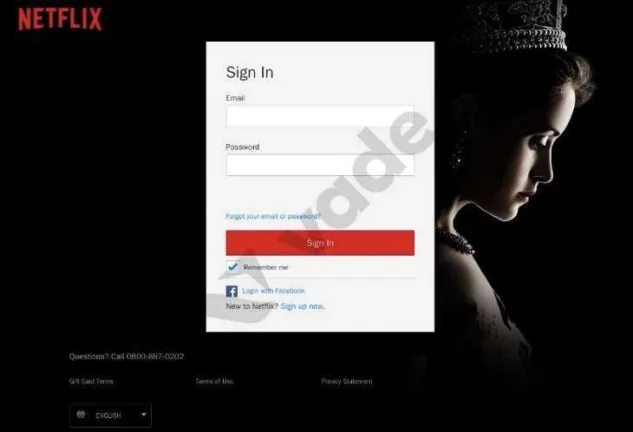
Liens douteux
Une autre méthode utilisée par les hackers consiste à diriger la victime vers un site Web frauduleux via un email de phishing. L’email de phishing vous demande de cliquer sur un lien vers un site Web qui semble être le véritable site Web d’une entreprise. Souvent, le lien prétend être le véritable site Web, mais il contient un sous-domaine qui vous mène ensuite vers un faux site Web.
Par exemple, l’email dit que vous devez vous connecter à Google pour changer votre mot de passe. Normalement, vous seriez dirigé vers un site web comme www.google.com/login, mais l’URL dans l’email pourrait ressembler à google.com.login.tinyurl.co. Dans ce cas, vous ne seriez pas dirigé vers google.com, mais vers tinyurl.co. Cela fonctionne même après un « / ».
Sur ces sites de phishing, ils veulent souvent que l’utilisateur saisisse un mot de passe, un code PIN ou quelque chose de similaire. Si vous recevez un email comme celui-ci, vous ne devez pas utiliser le lien qu’il contient. Si vous voulez être sûr que personne n’a volé vos identifiants, vous devez vous rendre sur le site web en saisissant vous-même l’URL dans votre navigateur web.
Faux champs de formulaire
Sur ces sites frauduleux, il existe une autre possibilité d’accéder à vos données sensibles. Vous avez du mal à vous souvenir de longs numéros ? Vous êtes ravi de pouvoir enregistrer les informations de votre carte de crédit sur Google, pour ne plus jamais avoir à les saisir ? Mais attention ! Les formulaires à remplissage automatique que vous proposent Google, Safari et tous les autres services présentent un risque important.
Les hackers peuvent placer un formulaire sur un site web en dehors de la zone visible, là où vous demandez les informations de votre carte de crédit. Ainsi, le cybercriminel vous conduit vers son faux site web, et là, on vous demande de saisir votre nom. Google vous propose d’utiliser son formulaire de saisie automatique. Ce que vous ne voyez pas, c’est le formulaire de carte de crédit, qui est également rempli automatiquement. N’enregistrez pas les détails de votre carte de crédit dans un outil de saisie automatique.
Langue
Si vous êtes américain, vous avez votre argent dans une banque américaine. Vous recevez maintenant un email qui semble provenir de votre banque, mais qui est écrit en espagnol. Maintenant, demandez-vous pourquoi ils vous enverraient un email en espagnol, même s’ils savent que vous parlez anglais ? Vous avez raison, le risque est élevé. Il s’agit d’une fraude et vous ne devez pas réagir. En outre, vous devriez vous méfier si vous recevez un email contenant des données importantes de votre banque, car normalement, elle vous les enverrait par email direct ou dans la boîte de réception de votre compte bancaire.
Chantage sexuel
Les escroqueries par chantage sexuel sont conçues pour faire croire aux victimes qu’un hacker informatique est en possession d’informations compromettantes, telles qu’une vidéo de la victime regardant de la pornographie en ligne. Ces escroqueries visent souvent les consommateurs de sites. La victime est invitée à payer le pirate informatique en bitcoins pour éviter que les informations ne soient divulguées au public et à ses connaissances.
Attaques de phishing d’entreprise
Le phishing était autrefois considéré comme un problème de consommation lorsqu’il est apparu au milieu des années 1990. Les hackers se faisaient alors passer pour des employés d’AOL afin d’exploiter les utilisateurs du service Internet. Mais à mesure que les attaquants se sont perfectionnés, ils ont commencé à cibler les entreprises, notamment les fournisseurs de services cloud, les institutions financières et d’autres grandes entreprises sur lesquelles les organisations s’appuient.
En 2013, le phishing est devenu le principal vecteur de distribution des ransomwares, une menace efficace pour s’emparer de données critiques et prendre en otage des organisations en échange d’une rançon.
Informations privées
Les cybercriminels tentent de voler vos données personnelles. Ils cherchent à obtenir des mots de passe, des codes PIN et des TAN. Une banque ne vous demanderait jamais de telles données dans un email. Si vous êtes invité à fournir ces données, vous pouvez être sûr que vous avez reçu un email de phishing. C’est aussi la raison pour laquelle les banques envoient toutes les informations importantes par courrier postal… ou dans les boîtes de réception de leurs propres applications bancaires/portails Internet.
Déficience grammaticale et orthographique
De plus, vous devez faire attention aux fautes d’orthographe ou de grammaire dans les phrases. Souvent, les emails de phishing sont rédigés dans une autre langue, puis simplement traduits à l’aide d’un traducteur en ligne. C’est pourquoi les emails de phishing contiennent souvent de nombreuses erreurs.
Comment se protéger contre le phishing ?
Pour se protéger contre le phishing, il est préférable de faire confiance à des solutions professionnelles de sécurité informatique.
Implémenter une authentification des emails
L’usurpation d’adresse email est une stratégie fondamentale des escroqueries par phishing. Les protocoles d’authentification des emails existent pour limiter la capacité des hackers à usurper l’identité des expéditeurs. Les protocoles d’authentification des emails, notamment Sender Policy Framework (SPF), Domain-Keys Identified Mail (DKIM) et Domain-based Message Reporting and Conformance (DMARC), constituent une couche de sécurité importante. Des recommandations détaillées pour la mise en œuvre de SPF, DKIM et DMARC sont disponibles auprès du NIST, et de nombreuses ressources et fournisseurs sont disponibles pour aider à l’adoption de DMARC.
Adopter une politique en matière d’email et de navigation sur le web
En plus de la formation de sensibilisation des utilisateurs, une politique en matière d’email et de navigation sur le Web aborde l’élément humain de votre stratégie globale de sécurité. Ces politiques définissent l’utilisation sûre et responsable de l’email et d’Internet au sein de votre organisation, en établissant des règles et des directives pour le traitement des informations sensibles et le respect des protocoles de sécurité.
Vous pouvez commencer par utiliser le modèle d’une institution respectée et le personnaliser en fonction des besoins spécifiques de votre organisation. Veillez à ce que la politique soit facilement accessible et intégrée à la formation des employés.
S’engager dans la formation de sensibilisation des
utilisateurs
Selon le rapport d’enquête sur les violations de données de Verizon, l’erreur humaine reste le principal facteur contribuant aux violations de données. La formation de sensibilisation des utilisateurs permet de limiter le risque d’erreur humaine en leur apprenant à identifier et à gérer correctement les dernières menaces et techniques de phishing.
Les meilleurs résultats de formation proviennent de programmes qui fournissent un enseignement basé sur la simulation par voie électronique, automatiquement et à la demande, selon les besoins des utilisateurs. Les programmes doivent également contextualiser la formation en fonction du rôle unique de chaque utilisateur, en tenant compte du fait que les menaces de phishing peuvent varier en fonction de la profession et de l’ancienneté de la victime ciblée. Cela contraste avec les programmes de formation traditionnels, qui utilisent des scripts de simulation génériques, suivent un calendrier prédéterminé et nécessitent une facilitation directe par un administrateur.
Parallèlement, les programmes de formation de sensibilisation des utilisateurs devraient leur apprendre à signaler les emails suspects. Cela donne aux administrateurs la possibilité d’enquêter et de remédier aux menaces potentielles.
Activer l’authentification multifacteur (MFA)
L’authentification multifacteur (MFA) renforce votre sécurité en exigeant des utilisateurs qu’ils authentifient leur identité par plusieurs moyens offrant chacun un niveau de sécurité. Des institutions telles que la CISA recommandent à toutes les organisations, en particulier aux petites et moyennes entreprises, d’adopter la MFA.
La meilleure pratique consiste à adopter une MFA basée sur FIDO ou PKI, qui offre une protection résistante au phishing. Si ces options ne sont pas réalisables, les meilleures alternatives sont l’authentification multifactorielle basée sur une application, par SMS ou vocale.
Adopter et appliquer des politiques strictes en matière de mots de passe
Les comptes compromis sont souvent exploités dans le cadre d’attaques de phishing ou de Business Email Compromise (BEC). Des politiques de mots de passe forts peuvent atténuer le risque que les utilisateurs créent des mots de passe faibles ou les réutilisent d’une application à l’autre. Pour créer une politique de mots de passe robuste, exigez des utilisateurs qu’ils définissent des mots de passe longs et uniques, car la longueur est plus importante que la complexité, selon le National Institute of Standards and Technologies (NIST).
Limitez le nombre de tentatives de mots de passe incorrects autorisées et développez et appliquez une liste de mots de passe inacceptables qui inclut des termes du dictionnaire, des noms spécifiques et des identifiants piratés.
Adopter une solution de sécurité de messagerie tierce et intégrée
Les solutions intégrées de sécurité des emails sont fortement recommandées pour contrer les menaces modernes par email. Selon le guide du marché de Gartner pour la sécurité des emails, les entreprises devraient compléter les fonctionnalités natives de leurs plateformes de messagerie avec cette technologie, en remplacement des solutions traditionnelles telles que les passerelles de messagerie sécurisées (SEG).
Les SEG fonctionnent en dehors du réseau interne d’une organisation et s’appuient sur des technologies qui basent la détection sur les attaques passées, plutôt que sur celles qui n’ont pas encore fait de victime. Les solutions intégrées comblent ces lacunes.
Elles existent au sein du réseau interne et offrent une protection contre les attaques externes et internes. Beaucoup utilisent également des algorithmes basés sur l’IA pour détecter et neutraliser les menaces qui n’ont pas encore émergé. Les meilleures solutions offrent des capacités avancées de prévention, de détection et de réponse aux menaces.
Votre solution de sécurité des emails vous protège-t-elle contre une attaque de phishing ?
Les entreprises sont de plus en plus souvent victimes d’attaques par email de phishing. En raison des revenus élevés que les attaquants peuvent tirer des entreprises, ils tentent de les atteindre avec leur escroquerie. Les dommages que ces attaques peuvent causer sont immenses. Par conséquent, vous devriez penser à la sécurité de vos emails.
Nos services de sécurité sont là pour protéger votre entreprise.
Pour protéger votre entreprise, les développeurs de Hornetsecurity ont inventé Advanced Threat Protection. ATP peut reconnaître les signes avant-coureurs des attaques par courrier électronique de phishing et, en particulier, les attaques ciblées, qui ne visent qu’une seule personne.
Comment puis-je éviter le phishing ?
Le phishing n’est pas un malware, c’est un outil d’escroquerie que les hackers utilisent pour tromper la sécurité de la victime par le biais d’un appel personnel. C’est pourquoi il n’y a aucune possibilité de supprimer les attaques de phishing. Si un hacker a votre adresse email, il peut toujours l’utiliser pour vous envoyer des emails de phishing. Vous ne pouvez qu’empêcher de recevoir davantage d’emails de phishing.
Pour prévenir le phishing (hameçonnage), la première chose à faire est de vous sensibiliser, vous et/ou vos employés, à regarder encore plus précisément les emails qui vous obligent à donner des données personnalisées. Si vous le faisiez, vous et/ou vos employés pourriez reconnaître toutes les attaques de phishing.
Pour vous sensibiliser, vous pouvez utiliser toutes les techniques de reconnaissance que je vous ai montrées ci-dessus. Pour tester vos connaissances, Google a inventé un quiz : https://phishingquiz.withgoogle.com/ Cela devrait minimiser le danger, mais il reste un risque si vous ne faites pas confiance à une solution professionnelle de sécurité informatique.
Comment le ATP fonctionne-t-il ?
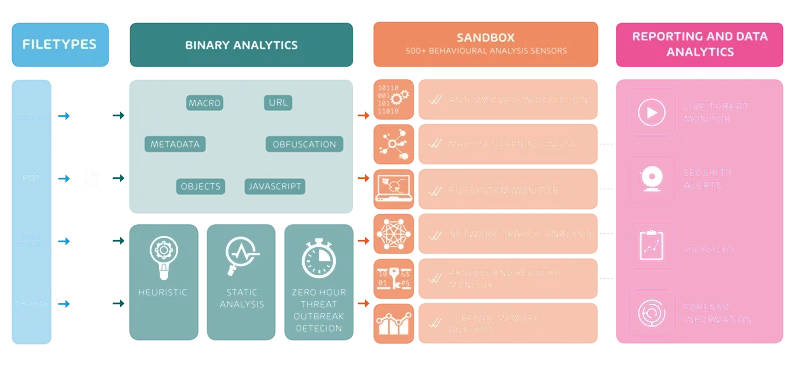
Hornetsecurity ATP vérifie que chaque email entrant ne contient pas de contenu malveillant. Pour ce faire, ATP place tous les fichiers, URL, etc. entrants dans un bac à sable. Dans le bac à sable, ATP exécute le contenu dans des systèmes d’exploitation virtuels. ATP recherche ensuite les effets dans les systèmes et d’autres anomalies. Si tout est normal, le destinataire reçoit l’email normalement. Lorsque ATP détecte un contenu malveillant, il le bloque et le destinataire reçoit une alerte de sécurité.
Comment améliorer la sécurité informatique grâce à la sensibilisation à la sécurité
Les employés sont en première ligne lorsque les pirates tentent d’exploiter les vulnérabilités techniques ou humaines. En formant vos employés, les entreprises réduisent le risque d’être victimes de cyberattaques. Le service de sensibilisation à la sécurité de Hornetsecurity propose une formation automatisée à la sensibilisation à la sécurité et des simulations de phishing.
Toutes les informations résumées
L’Infopaper suivant sur le phishing résume clairement les recommandations des experts de Hornetsecurity. Téléchargez-le dès maintenant et accédez à des conseils pour détecter et prévenir les attaques de phishing, ainsi qu’aux actions recommandées pour le pire des scénarios.
Découvrez les services HORNETSECURITY


Vous souhaitez approfondir des sujets liés à la cybersécurité ?
Si notre article sur le phishing vous a plu, vous aimerez sans doute d’autres contenus de notre base de connaissances ! Découvrez des ressources sur Emotet, les chevaux de Troie, la sécurité informatique, les ransomwares, le phishing ou encore les virus informatiques.