

Cet article est le premier d’une série de trois portant sur les difficultés inhérentes à la détection des attaques de phishing, en particulier dans le cadre de fortes contraintes de volume, précision et performance. Dans cet article, nous décrirons comment sont extraits des flux d’emails les liens suspects, et également la manière dont est obtenu le contenu des pages web associées.
Dans l’article suivant, nous expliquerons comment les pages web suspectes sont analysées et évaluées en temps réel, notamment au moyen de techniques d’apprentissage supervisé. Enfin, le dernier article s’intéressera aux avantages du Deep Learning et de la Computer Vision dans le but d’extraire des informations supplémentaires et de permettre ainsi la détection d’attaques plus complexes.
Sélection des URL candidates
Afin d’assurer la protection de plus d’un milliard de comptes de messagerie électronique dans le monde, Vade collecte de très nombreuses URL - plus d’un milliard d’URL uniques par jour en moyenne. En raison de l’impossibilité technique d’évaluer chaque URL, des techniques de filtrage, basées sur un éventail de critères, ont été mises en place. Ainsi, seules les URL qui comportent un risque sont analysées.
Le premier critère d’évaluation est la réputation du domaine de l’URL. La réputation d’un domaine dépend principalement du nombre d’URL malveillantes détectées dans le passé qui lui sont associées. Le fait qu’un domaine soit connu n’est pas nécessairement synonyme d’une bonne réputation. Ainsi, de nombreux domaines connus sont utilisés par des cybercriminels, comme par exemple les raccourcisseurs d’URL (Bitly, TinyURL, etc.), les services d’hébergement web (Weebly, Yola, etc.) ou encore les services d’hébergement de fichiers (tels que Dropbox). Même google.com, sans doute le domaine le plus connu du monde, est utilisé pour rediriger vers du contenu malveillant.
De leur côté, les domaines inconnus sont considérés par défaut comme suspects du fait de l’absence de données historiques qui permettent de calculer des éléments de réputation. Tout pic d’activité soudain - caractéristique des cyberattaques - est également considéré comme suspect. Dans le cas présent, l’analyse de chaque URL n’est pas nécessaire, et un échantillonnage aléatoire est effectué. Cet échantillonnage est répété périodiquement afin de détecter les pages web de phishing dont l’activation est différée.
En dernier lieu, la source de l’URL est considérée, avec une priorité donnée aux emails signalés par les utilisateurs comme étant des faux négatifs, ainsi qu’aux emails collectés par des spam traps. Au terme de cette étape de filtrage, nous disposons d’une liste d’URL prêtes à être scannées. En moyenne, le scanner d’URL de Vade analyse plus de 20 millions d’URL par jour, ce qui représente environ 5 % du nombre total d’URL uniques collectées.
Gestion des « dommages collatéraux »
L’analyse d’une URL peut avoir des conséquences inattendues, comme la désinscription d’un utilisateur d’une liste de diffusion. Il s’agit de dommages collatéraux qu’il faut à tout prix éviter. Pour cela, une des solutions consiste à vérifier que le même lien a été reçu par différents utilisateurs. En effet, il est peu probable que ce lien contienne des données personnelles s’il a été reçu par différents utilisateurs. Une telle méthode présente toutefois des inconvénients. Tout d’abord, elle retarde l’analyse du lien, puisqu’un délai est nécessaire pour vérifier la réception du lien par plusieurs utilisateurs. En outre, les liens de phishing « personnalisés » ne peuvent être détectés. Par exemple : cette campagne de phishing, qui usurpe l’identité de la Banque royale du Canada, aurait échappé à la détection, car chaque lien est personnalisé à l’aide d’un token hexadécimal aléatoire présent dans le path de l'URL.

Chaque URL de phishing est unique
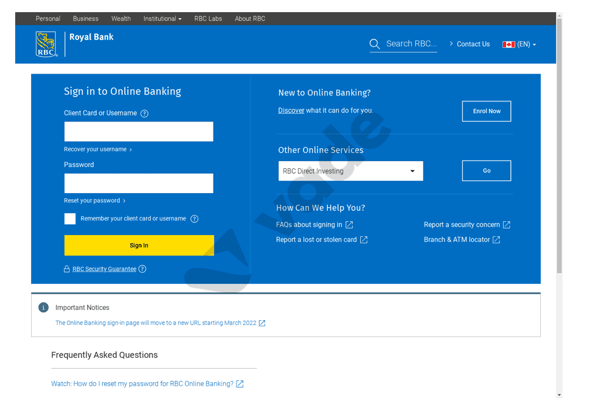
Phishing de la Banque royale du Canada
Notre scanner a recours à une autre technique qui est brevetée. Il analyse le path et la query string de l’URL candidate afin d’identifier les éléments susceptibles d’être associés à un utilisateur. Ensuite, ces éléments sont remplacés par des éléments générés aléatoirement, qui respectent le format original, comme la longueur, le type d’encodage (décimal, hexadécimal, Base64, etc.) ainsi que la casse (majuscule, minuscule).
Si l’URL s’avère inoffensive et contient des données associées à un utilisateur, alors l’analyse de l’URL réécrite ne provoquera aucun dommage collatéral : le site web renverra typiquement une erreur client HTTP 4xx, car les éléments modifiés ne correspondront à aucune données réelles (Enregistrements en base de données, etc.). Si l’URL s’avère être une URL de phishing, elle sera tout de même acceptée par le kit de phishing, car ce dernier ne fait aucune corrélation entre ces éléments et les destinataires de la campagne de phishing. Dans le pire des cas, une expression régulière (ou mécanisme de contrôle équivalent) sera appliquée par le kit afin de vérifier la validité du format de l’URL.

Le token hexadécimal a été généré à la volée pour éviter les dommages collatéraux
Contournement des mécanismes défensifs
Afin d’évaluer l’URL candidate, cette dernière doit être « scannée », ce qui implique de récupérer le contenu HTML associé à l’URL en effectuant une requête HTTP GET. En premier lieu, avant d’accéder au site de phishing final, il peut s’avérer nécessaire de suivre un ou plusieurs liens de redirection, comme les redirections HTTP, les redirections de type meta refresh ou encore les redirections JavaScript. À l’instar de n’importe quel autre client HTTP, le scanner qui se connecte au serveur lors de la requête HTTP GET expose son adresse IP et définit des headers HTTP, comme par exemple les headers User-Agent et Accept-Language.
Ces données de connexion sont utilisées par de nombreux sites web pour personnaliser l’expérience utilisateur. Par exemple, si la connexion provient d’un pays donné, alors l’utilisateur est éventuellement redirigé vers le site web spécifique pour ce pays. De même, le header User-Agent permet d’identifier hardware et le software utilisés pour parcourir le site web, ce qui permet au site web de présenter un contenu adapté - à la taille de l’écran par exemple. Enfin, le header Accept-Language définit les paramètres régionaux souhaités par l’utilisateur (langue, format de la date et de l’heure, unité monétaire, etc.).
Les kits de phishing sont également en mesure de fournir du contenu personnalisé, mais dans une moindre mesure. De plus, ces données seront utilisées afin de détecter les bots et autres scanners de contenu web. A ce stade, nous classerons les kits de phishing en trois catégories distinctes.
La première, et la moins élaborée, renvoie le contenu des pages web sans tenir compte des paramètres de connexion du client HTTP. La deuxième, la plus fréquente, retourne par défaut le contenu des pages web de phishing – à l’exception de certains cas. Un exemple est le filtrage de l’adresse IP de connexion ou de certains headers HTTP. L’objectif de ce type de kit est de détecter les bots et autres scanners et, le cas échéant, de renvoyer un code d’erreur HTTP ou de rediriger vers un autre site web, tel que Google.
La troisième catégorie de kits de phishing est, du fait de sa complexité, la plus rare. Par défaut, elle applique la politique du « Deny all » et retourne le contenu de la page web de phishing uniquement lorsque certaines conditions sont réunies. Cette catégorie de kit de phishing est évidemment la plus difficile à détecter. Pour autant, elle n’est que peu répandue, car elle limite le nombre de victimes potentielles si les conditions fixées sont trop restrictives. À titre d’exemple, une des conditions requises serait que la victime se connecte depuis un pays donné avec un équipement, système d’exploitation et logiciel spécifiques (Par exemple, une version particulière d’iPhone).
Pour illustrer l’utilisation du deuxième kit de phishing, penchons-nous sur un kit de phishing Wells Fargo détecté récemment, qui met en place un mécanisme de filtrage permettant de détecter les bots. Le kit compare tout d’abord l’adresse IP de connexion du client HTTP à une liste de plages d’adresses IP connues. Ces plages d’adresses IP sont celles de fournisseurs de solutions de sécurité, de services d’hébergement et autres organisations. Si l’adresse IP de connexion appartient à une des plages listées, alors le kit renvoie un message d’erreur 404.

Plages d’adresses IP de fournisseurs de solutions de sécurité connues par le kit de phishing
Le kit réalise également un filtrage du hostname associé à l’adresse IP de connexion. La liste des plages d’adresses IP étant rarement exhaustive, les cybercriminels utilisent le fait que de nombreuses organisations utilisent une convention de nommage pour leurs enregistrements DNS. Ainsi, le kit détermine le hostname à l’aide de la fonction PHP gethostbyaddr() et le compare à une liste de mots-clés identifiant des fournisseurs de solutions de sécurité, des entreprises technologiques et également le réseau Tor. En cas de correspondance du hostname avec un de ces mots-clés, une erreur HTTP 404 est retournée.
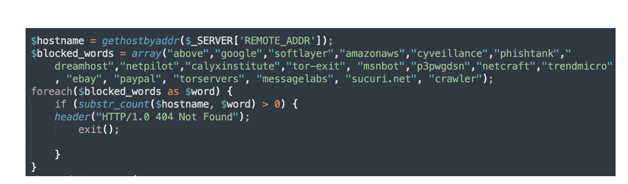
Recherche DNS inversée et filtrage du hostname
Le kit contrôle également le header HTTP User-Agent. Lorsqu’un utilisateur se connecte à un site web, le User-Agent permet d’identifier le type d’équipement (iPhone, Samsung Galaxy, Google Pixel, iPad, etc.), le système d’exploitation (iOS, Android, etc.) et le logiciel utilisé pour la navigation (Safari, Firefox, Chrome, etc.). L’objectif pour le kit est de détecter les connexions de bots - comme les robots d’indexation, scanners et autres processus automatisés. Ici, le kit compare le header User-Agent à une liste de mots-clés, y compris des robots d’indexation connus (Googlebot, Bingbot, etc.). Comme précédemment, le kit renvoie une erreur HTTP 404 en cas de correspondance.

Filtrage du header HTTP User-Agent
Les kits de phishing utilisent une multitude de mécanismes de filtrage (scripts, listes de plages d’adresses IP, listes de mots-clés). On observe d’ailleurs que les cybercriminels ne semblent pas partager ces mécanismes entre eux, l’écosystème du cybercrime étant davantage concurrentiel que collaboratif. En effet, lorsqu’une plage d’adresses IP d’un fournisseur de solutions de sécurité spécifique est filtrée par l’un des kits de phishing, cela ne signifie pas pour autant qu’elle soit filtrée par d’autres kits. Il est toutefois fort probable que la plage d’adresse IP en question soit connue au bout d’un certain temps.
En réponse à ces mécanismes défensifs, notre scanner met en place différentes méthodes pour diminuer le risque d’être détecté par les kits de phishing. Premièrement, il utilise un grand nombre d’adresses IP distinctes, réparties dans de nombreuses plages d’adresses IP et localisées dans une dizaine de pays (Japon, États-Unis, Nouvelle-Zélande, Australie, Brésil, France, Royaume-Uni, Allemagne, Italie et Espagne). En outre, l’enregistrement DNS de chaque adresse IP ne donne aucun indice aux kits de phishing et peut être confondu avec une adresse IP utilisée par un utilisateur lambda. Pour garantir l’efficacité de notre scanner dans le temps, nous collectons et analysons régulièrement des kits de phishing. La collecte des kits de phishing est rendue possible par le fait que certains sites web hackés hébergeant des kits de phishing soient mal sécurisés - ce qui explique d’ailleurs pourquoi ils ont été initialement piratés.
Chaque kit est contrôlé automatiquement pour s’assurer que les adresses IP, plages d’adresses IP et enregistrements DNS utilisés par notre scanner ne sont pas connus. Si c’est le cas, nous agissons en conséquence, et remplaçons les adresses IP, avec les enregistrements DNS adéquats. Par ailleurs, notre scanner utilise un pool de User-Agents qui simule les cas d’usage les plus communs, comme par exemple Safari sur iPhone, ou bien Chrome ou Firefox sur Windows. Cette méthode permet de contourner les mécanismes de filtrage du User-Agent.
En ce qui concerne la catégorie de kits de phishing la plus sophistiquée, qui refuse toutes les connexions HTTP à moins qu’elles réunissent un ensemble de conditions spécifiques, nous avons mis au point un algorithme qui permet de déterminer les meilleurs paramètres pour analyser les URL suspectes extraites d’un email. Ces paramètres peuvent inclure la géolocalisation de l’adresse IP, et les headers HTTP tels que User-Agent, Accept-Language et Referrer. Cet algorithme breveté réduit la probabilité qu’un kit de phishing particulièrement sophistiqué détecte notre scanner.
Prenons pour exemple l’email de phishing décrit dans le brevet (Figure 5). Selon toute vraisemblance, cet email de phishing cible uniquement des utilisateurs italiens, comme suggéré par plusieurs indices. L’email de phishing usurpe l’INPS (Istituto Nazionale Previdenza Sociale), qui est la principale entité du système public de retraite italien. Le texte contenu dans l’email est rédigé en italien et le TLD (Top Level Domain) de l’expéditeur est « .it » - le TLD utilisé pour l’Italie. Compte tenu de ces éléments, l’algorithme peut déterminer la meilleure stratégie, qui consiste à effectuer l’analyse de l’URL à partir d’une adresse IP géolocalisée en Italie en configurant le header Accept-Language avec le code language « it-IT ». Après avoir récupéré le contenu de la page web suspecte, il est possible d’analyser le contenu et de déterminer son éventuel caractère malveillant.
Dans le prochain article, nous présenterons les différentes technologies utilisées en temps réel par notre scanner pour évaluer le contenu d’une page web. En particulier, nous nous intéresserons aux techniques d’apprentissage supervisé.



