

This article is the first of a series of three related to the challenges that we faced to detect phishing attacks at scale with constraints on accuracy and performance. In this article, we will describe how—starting mainly from the email stream—we identify suspicious links and then fetch the content from the associated webpages. In the next article, we will describe how suspicious webpages are analyzed and assessed in real-time, with a focus on Supervised Learning techniques. In the final article, we will reveal how Deep Learning and Computer Vision can be leveraged to extract additional information and automate detection of more complex cases.
Selection of candidate URLs
Vade protects more than 1 billion mailboxes worldwide and as such collects a large number of URLs—an average of more than 1 billion URLs every day. As it is technically impossible to scan each URL, filtering techniques based on multiple criteria have been implemented so that only the most relevant URLs are extracted and scanned.
First, the reputation of the URL domain is considered. Domain reputation largely depends on the ratio of malicious URLs associated with this domain and detected in the past—the fact that a domain is well known does not imply that it has a good reputation.
Many well-known domains are abused by cybercriminals, such as shortening services domains (Bitly, TinyURL, etc.), web hosting services (Weebly, Yola, etc.), and file-hosting services (Dropbox, etc.). Even google.com—probably the most popular domain in the world—can be abused to redirect to malicious content.
Unknown domains are considered suspicious because there is no historical reputation data attached. Any ‘burst’ activity will also be considered suspicious, as it is the typical modus operandi of cyberattacks. In this case, a random sampling will be performed because it is not necessary to scan each URL. The sampling will be performed periodically to allow detection of phishing webpages whose activation is delayed.
Finally, the source of the URL will be considered. In particular, emails that have been reported by end users as a false negative or emails that have hit a spam trap will be processed in priority. After this filtering, we have a list of URLs that are ready to be scanned. On average, Vade's URL scanner processes more than 20 million URLs per day, which represents five percent of the total number of URLs collected.
Dealing with ‘collateral damages’
Scanning a URL may have unexpected consequences, such as unsubscribing a user from a mailing list, so it is important that we limit these potential collateral damages. One way to limit these damages is to ensure that several users have received the same link. It is unlikely that the link contains personal data if it has been received by several users. This method, however, has several drawbacks: It delays the processing of the link, as there is a latency to ensure that several users have received the same link, and ‘personalized’ phishing links will not be scanned. For instance, the following Royal Bank of Canada phishing campaign would not be detected because each link is personalized with a random hexadecimal token in the URL path.
 Figure 1 Each phishing URL is unique
Figure 1 Each phishing URL is unique
Figure 2 Royal Bank of Canada phishing
Our scanner uses another technique that has been patented. It analyzes the file path and query string of the candidate URL, and then identifies elements that may be linked to a user. These elements are then replaced with randomly generated elements that respect the format of the original ones, such as the length, the encoding type (Decimal, hexadecimal, Base64, etc.), and the letter case (uppercase, lowercase).
In the case where the URL is benign and contains personal data, then the scan of the rewritten URL will not lead to collateral damage—the website will probably return a HTTP 4xx client error because the modified elements will not be found in the database. In the case where the URL is a phishing URL, then it will still be accepted by the phishing kit, as the elements will not be matched against a database. In the worst-case scenario, a regular expression or equivalent control mechanism will be applied to check that the URL format is valid.
 Figure 3 The hexadecimal element has been generated on the fly to prevent collateral damage.
Figure 3 The hexadecimal element has been generated on the fly to prevent collateral damage.
Evading cloaking techniques
To evaluate the candidate URL, it is necessary to ‘scan’ the URL; in other words, to fetch the HTML content associated with the URL by performing a HTTP GET operation. First, before reaching the final phishing website, it may be necessary for the scanner to follow one or several redirections, such as HTTP redirections, meta-refresh redirections, or JS redirections. When the final phishing webpage is reached, the scanner—like any other HTTP client—exposes its IP address and may set some HTTP headers, such as the User-Agent and Accept-Language header, when it performs the HTTP GET operation.
Many websites use these data to personalize the user experience. For instance, if the connection originates from a certain country, then the user may be redirected to the specific website for this country, and content may be delivered in the prevailing language. Similarly, the User-Agent header specifies the device and software used to browse the website, and Accept-Language defines the preferred language and locale for the user, which allows the website to provide tailored content to the end user.
Phishing kits may also provide personalized content, although to a lesser extent; however, they will also use these data to deter detection by bots and security scanners. At this point, we can classify phishing kits into three distinct types.
The first and least sophisticated returns the content of the webpage regardless of the HTTP client connection parameters. The second type, which is rather common, returns the content of the phishing webpage unless certain conditions are met. For instance, there may be filtering on the connecting IP address or on the HTTP headers. The goal of the kit is to detect bots and return a HTTP error code or redirect to another website, such as Google, in case a bot is detected.
The third type of phishing kit is the rarest of all and the most sophisticated. It applies a ‘deny all’ policy by default and will return the content of the phishing webpage only if a set of conditions are met. This type of phishing kit is the most difficult to detect; however, it is not widespread because it limits the number of potential victims if the conditions are too restrictive. One example of a required condition is that the victim must connect from a specific country with a specific device.
To illustrate the second type of phishing kit, let’s have a look at a recent Wells Fargo phishing kit that implements filtering to deter bots. The kit first compares the connecting IP to a list of known IP ranges. These IP ranges are associated with security vendors, hosting companies, and other organizations. If the connecting IP belongs to one of the ranges listed, then the kit returns a HTTP 404 error.
 Figure 4 Security vendors’ IP ranges detected by the phishing kit
Figure 4 Security vendors’ IP ranges detected by the phishing kit
The kit also performs additional filtering on the hostname associated with the connecting IP. In fact, as the list of IP ranges may not be exhaustive and up to date; the phishers take advantage of the fact that many organizations apply a naming pattern for their DNS records.
The kit first gets the hostname associated with the IP with the gethostbyaddr() PHP function, and then compares the value to a list of keywords that includes security vendors and organizations, technology companies, and the Tor network. If the value matches one of these keywords, then once again an HTTP 404 error is returned.
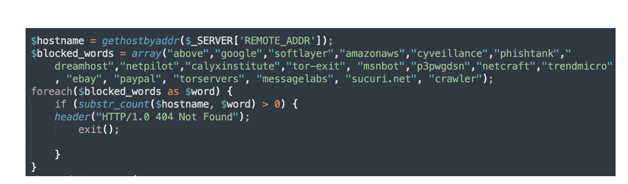 Figure 5 Reverse DNS lookup and filtering of hostname
Figure 5 Reverse DNS lookup and filtering of hostname
The kit also checks the HTTP User-Agent header. The User-Agent is used by the HTTP client to identify itself. For instance, in the context of an end user browsing with a computer or a smartphone, the User-Agent typically describes the device, OS (iOS, macOS, Windows, etc.), and software (Safari, Firefox, Chrome, etc.). The kit’s goal is to detect connections by bots such as web crawlers or other automated processes. The kit here compares the User-Agent with a list of keywords, including known web crawlers (Googlebot, Bingbot, etc.). As previously, the kit returns an HTTP 404 error in case of a match.
 Figure 6 Filtering of HTTP User-Agent header
Figure 6 Filtering of HTTP User-Agent header
Phishing kits use different filtering mechanisms—scripts, lists of IP ranges, keywords—from one to another. It is reasonable to assume that phishers don’t collaborate with each other and that the phishing ecosystem is more competitive than collaborative. The fact that a specific security vendor's IP range is filtered out in one phishing kit does mean that it is also filtered out in other phishing kits. It is likely, however, that the specific IP range will be known within the phishing ecosystem after a while.
To address these challenges, our scanner implements several mechanisms that drastically limit the likelihood of being identified by phishing kits. First, it uses many different IP addresses scattered in different IP ranges and located in 10 different countries (Japan, USA, New Zealand, Australia, Brazil, France, UK, Germany, Italy, and Spain). Furthermore, the DNS record of each IP address does not alert phishing kits and could be mistaken with a residential IP address. To ensure that our scanner remains efficient over time, we regularly collect and analyze phishing kits. The collection of phishing kits is possible because compromised websites that host phishing kits are sometimes left unsecured.
Each kit is checked automatically to ensure that the IP addresses, IP ranges, and DNS records we use are not known. If this is the case, then we act accordingly and purchase new IP addresses with DNS naming patterns not known by the kits. Additionally, our scanner uses a pool of User-Agents that simulate the most common devices, OS, and browser combinations, such as Safari on iPhone, and Chrome and Firefox on Windows. Thus, User-Agent filtering mechanisms are bypassed.
Regarding the most sophisticated type of phishing kit that denies all HTTP connections unless it matches a set of specific conditions, we have designed an algorithm that determines the best HTTP parameters to scan the suspect URLs in a given email. These parameters can include IP address geolocation; HTTP headers, such as User-Agent; Accept-Language; and Referrer. This algorithm has been patented, and it reduces the likelihood that the most sophisticated phishing kits will take any defensive action against our scanning technology.
Let’s take the example of the phishing email described in the patent (Fig. 5). It is very likely that this phishing email is targeting only Italian users, as there are several clues that this attack is specific to the Italian context: The phishing email impersonates the main institution of the Italian public pension system called INPS (Istituto Nazionale Previdenza Sociale), the textual content of the email is written in the Italian language, and the TLD of the sender email address is ‘it.’ Considering these elements, the algorithm determines that the best strategy is to scan from an IP address geolocated in Italy and set the Accept-Language header to ‘it-IT’ language code. Once the webpage of the candidate URL has been fetched, it is then possible to analyze the content and determine if it is malicious.
In the next article, we will present the different technologies used in real-time by our scanner, and more specifically supervised classification techniques.



