

Cet article est le deuxième d’une série de quatre publications portant sur les défis inhérents à la détection des attaques de phishing, en particulier dans le cadre de fortes contraintes de volume, précision et performance. Dans le premier article, nous avons présenté notre méthode de détection des liens suspicieux au sein d’un flux d’emails et la récupération des pages web associées. Notre deuxième article sera consacré à notre méthode d’analyse de ces pages web, notamment en utilisant l’Apprentissage Supervisé. Enfin, dans les deux derniers articles, nous explorerons plus en détail l’utilisation de
l’Apprentissage Profond (Deep Learning).
Gagner en précision en combinant les couches de détection
Après avoir récupéré la page web de l’URL candidate, il est possible d’analyser la paire URL/page web afin de déterminer son éventuel caractère malveillant. Lors du développement du scanner IsItPhishing.AI, nous avons convenu deux objectifs. Premièrement, s’engager à ne faire aucun faux positif, ce qui signifie concrètement que nous ne devons jamais classer un lien légitime en tant que phishing. Deuxièmement, tenter d’identifier la marque usurpée - une métadonnée particulièrement importante. En outre, même si la décision reste binaire du point de vue du client (lien de phishing ou lien légitime), nous avons ajouté un statut supplémentaire en interne : le statut « suspect ». Ce statut nous permet de traquer les nouvelles menaces et de conduire en temps réel des tests qui répondent à notre objectif « zéro faux positif ». Nous allons à présent décrire les différentes couches de détection, ainsi que leurs avantages et inconvénients respectifs.
La première couche d’analyse, le « Smart Pattern », est une technologie similaire à YARA. Chaque smart pattern se compose d’un ensemble de chaînes de caractères et d’expressions régulières appliquées sur la paire URL/page web et articulées selon une logique booléenne. Dans la plupart des cas, le smart pattern est associé à une marque spécifique, comme c’est le cas dans la majorité des attaques de phishing. Certaines situations font toutefois exception, c’est notamment le cas lorsque nous détectons une technique spécifique employée dans plusieurs kits de phishing, quelle que soit la marque.
Les smart patterns se divisent en deux ensembles : bloquants et non-bloquants. Le premier ensemble bloque toute paire URL/page web correspondant à un smart pattern bloquant. Il s’avère donc particulièrement efficace pour identifier les menaces connues et leurs variantes. Le second ensemble, lui, sert à découvrir de nouvelles menaces. Une confirmation est toutefois nécessaire pour bloquer la paire URL/webpage, qu’elle soit automatique ou basée sur des technologies plus complexes (Apprentissage Profond, Vision Numérique), ou encore effectuée manuellement par un analyste en cybersécurité. Si, à long terme, un smart pattern non bloquant détecte de nouvelles attaques de phishing sans déclencher de fausses alertes, il sera alors promu en tant que smart pattern bloquant. Dans le cas contraire, le smart pattern est amélioré jusqu’à atteindre la précision voulue, ou simplement abandonné s’il ne mène à rien.
Chaque fois que la couche Smart Pattern est mise à jour, elle est évaluée sur un corpus de validation. Cette approche élimine les risques de régression, elle est donc indispensable pour atteindre notre objectif de zéro faux positif. Si le test est concluant, la nouvelle version peut alors être déployée en production. Le corpus de validation est lui aussi mis à jour de façon régulière, pour s’adapter aux évolutions du web. Bien que simple et efficace, la couche Smart Pattern présente certaines limites. Tout d’abord, elle retourne une décision binaire, à l’instar d’un arbre de décision, ce qui ne permet pas de paramétrer un seuil de décision continu. Ensuite, cette technique étant de nature réactive, elle échoue à détecter de nombreuses menaces inconnues.
La seconde analyse repose sur un modèle d’Apprentissage Supervisé. Dans ce cas, des caractéristiques numériques et catégorielles sont extraites de la paire URL/page web afin de créer un « vecteur de caractéristiques ». Ce dernier est alors transmis au modèle d’Apprentissage Supervisé qui calcule la probabilité que la paire URL/page web soit du phishing. En fonction du résultat, la paire URL/page web est considérée comme du phishing (très haute probabilité), suspecte (haute probabilité) ou bien légitime. Conformément aux bonnes pratiques, le modèle d’Apprentissage Supervisé a été entraîné au préalable sur un jeu de données d’apprentissage étiqueté et ses performances évaluées sur un jeu de données de test distinct.
Loin d’être récent, l’emploi des algorithmes d’Apprentissage Supervisé pour la détection du phishing est même très bien documenté. L’Apprentissage Supervisé répond aux limites du Smart Pattern, puisque la probabilité retournée par le modèle permet de paramétrer un seuil de décision. Bien calibré, le modèle est alors en mesure de généraliser, c’est-à-dire de détecter des menaces inconnues. Les deux techniques sont toutefois complémentaires, car le Smart Pattern peut détecter les données aberrantes d’un point de vue statistique, qui posent beaucoup de difficultés au modèle d’Apprentissage Supervisé, notamment en raison de la contrainte imposée par le taux de zéro faux positif.
Modèles d’Apprentissage Supervisé : une affaire d’équilibre
À ce stade, il convient de définir certaines des notions employées, qui échappent peut-être au lecteur. Lors de la production d’un modèle d’Apprentissage Supervisé, deux écueils doivent être évités : le sur-apprentissage et le sous-apprentissage. Le sur-apprentissage survient lorsque la frontière de décision du modèle est trop proche des données d’apprentissage, modèle qui par conséquent échoue à prédire avec précision les observations futures. En d’autres termes, le modèle ne parvient pas à « généraliser », c’est à dire à faire de bonnes prédictions sur des données inconnues différentes des données d’apprentissage.
Bien souvent, la cause est un surentraînement du modèle, qui ne parvient pas à capturer la tendance statistique dominante des données d’apprentissage. L’erreur s’explique donc par un modèle qui produit de trop bonnes performances sur les données d’apprentissage, et des performances médiocres sur des données de test inconnues, en raison d’une incapacité à généraliser. A l’opposé du sur-apprentissage, le sous-apprentissage résulte d’un modèle insuffisamment entraîné et d’une frontière de décision inadaptée aux données d’apprentissage, ce qui engendre un taux élevé d’erreurs sur les données d’apprentissage comme sur les données de test.
De nombreuses techniques ont été proposées pour trouver le bon équilibre entre sur-apprentissage et sous-apprentissage, comme la sélection des caractéristiques, les méthodes ensemblistes (bagging, boosting) et la validation croisée de type k-fold. Toutefois, même avec une frontière de décision bien calibrée, la présence de données aberrantes est toujours possible, données aberrantes qui ne seront pas correctement détectées par le modèle d’Apprentissage Supervisé. Dans ce cas, une technique complémentaire, telle que la technologie Smart Pattern, peut être employée sans qu’il soit nécessaire de modifier le modèle d’Apprentissage Supervisé.
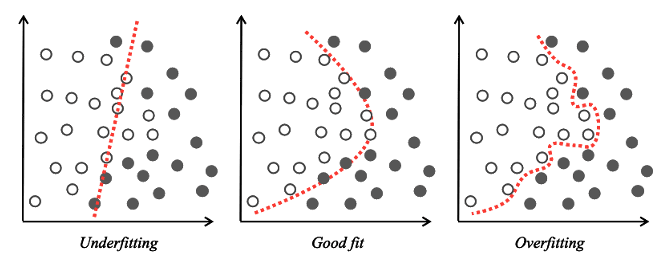
Illustration 1 Frontière de décision : sous-apprentissage, bon ajustement et sur-apprentissage
Extraction des caractéristiques
Durant la phase d’Apprentissage Supervisé, notre couche d’analyse extrait un total de 52 caractéristiques de la paire URL/page web : 17 proviennent de l’URL et 35 du document HTML. Pour choisir ces caractéristiques, nous nous basons principalement sur notre propre expérience et expertise, ainsi que sur la littérature scientifique existante, riche en précieuses informations qui corroborent la plupart de nos conclusions.
Attention : l’extraction de 52 caractéristiques ne signifie pas pour autant qu’elles seront toutes utilisées. Pour éviter le sur-apprentissage, seules les caractéristiques les plus pertinentes statistiquement seront conservées dans le modèle. À présent, examinons de plus près ces caractéristiques. Certaines sont typiques d’un site web de phishing, alors que d’autres sont représentatives d’un site web légitime et inoffensif.
Parmi les caractéristiques typiques du phishing, on peut citer la présence du nom de domaine d’une marque dans le sous-domaine de l’URL. Cet emplacement est choisi par le phisher pour une raison bien simple, à savoir induire en erreur les utilisateurs sur smartphone, puisque l’adresse affichée dans la barre de navigation est généralement tronquée, et la fin de l’URL n’est donc pas visible.
L’utilisateur pensera alors se connecter au site web légitime. La Figure 2 montre un exemple de ce subterfuge avec la banque Sparkasse, où le début de l’URL peut être aisément confondu avec la page authentique https://sparkasse.de. Par ailleurs, le stratagème est décliné en plusieurs variantes. Parfois, c’est le domaine de premier niveau qui passe à la trappe, ou bien des coquilles sont insérées pour contourner les technologies de détection, comme démontré en Figure 3. En présence d’une coquille, il est nécessaire d’utiliser un algorithme de distance d’édition plutôt qu’une correspondance stricte des chaînes de caractères pour trouver la corrélation avec le nom de domaine, ici amazon.co.jp.

Figure 2 URL de phishing Sparkasse

Figure 3 URL de phishing Amazon Japon
Pour les sites web légitimes, d’autres caractéristiques peuvent être utilisées. On pensera notamment à la présence d’une URL HTTPS, qui nous indique que la communication entre l’utilisateur et le site web est chiffrée. Néanmoins, il faut noter que cette caractéristique perd en pertinence avec le temps. En règle générale, le conseil donné aux utilisateurs était de vérifier la présence du HTTPS et d’une icône de cadenas dans la barre de leur navigateur avant de partager des informations sensibles avec un site web. Cette précaution ne garantit toutefois aucunement le caractère légitime d’un site web. Au contraire, une hausse vertigineuse du nombre de sites de phishing utilisant le HTTPS a été constatée à partir de 2017. Dans ce cas de figure, il est donc nécessaire de vérifier la pertinence statistique d’une caractéristique par rapport aux données récemment collectées. Si la caractéristique n’est pas jugée utile, elle ne doit pas être conservée dans le modèle.
La présence d’une URL HTTPS ne permet pas d’identifier une marque en particulier. En revanche, le nom de domaine de la marque, dans le sous-domaine d’une URL, fait spécifiquement référence à cette dernière (par exemple, Sparkasse ou Amazon Japon). La spécificité et la nouveauté de notre approche brevetée d’Apprentissage Supervisé repose sur notre méthode d’extraction des caractéristiques liées aux marques, qui permet d’améliorer la précision et de détecter la marque usurpée. De cette façon, nous sommes en mesure d’alerter les marques dont la réputation est ternie par les attaques de phishing. Prévenues à temps, ces marques peuvent à leur tour réagir, par exemple en avertissant leur clientèle et en demandant la fermeture du site web frauduleux. Vous pouvez d’ailleurs vous inscrire aux notifications d’alerte de Vade à destination des marques sur IsItPhishing.AI.
Il est possible de détecter une marque de différentes manières. Nous pouvons par exemple rechercher, dans le sous-domaine, une référence à la marque, comme c’est le cas en Figure 2 et Figure 3. Cet indice évident est malheureusement absent de la vaste majorité des URL de phishing. Nous pouvons également examiner la page web et trouver des artefacts visuels faisant référence à une marque. Un logo, par exemple. Si tentante qu’elle puisse paraître, cette approche n’est hélas pas réalisable en temps réel, car elle requiert au préalable de charger et d’effectuer le rendu graphique de la page web, puis d’exécuter des algorithmes de Vision Numérique pour détecter ces artefacts visuels, une technique que nous présenterons dans notre dernier article.
Une autre approche consiste à examiner le contenu HTML de la page web afin de déterminer si une proportion significative des ressources (images, icônes, fichiers CSS et scripts) sont récupérées à partir des domaines d’une marque spécifique. En effet, les marques hébergent les ressources de leurs sites web sur un nombre restreint de domaines de haute réputation, comme le domaine principal de la marque ou les domaines de content delivery network (CDN). Le tableau Figure 4 donne des exemples de domaines utilisés par Chase, Bank of America, PayPal, Sparkasse et Amazon Japon afin de stocker des ressources web.
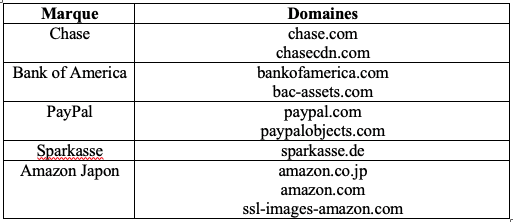
Figure 4 Domaines utilisés par plusieurs marques
Pour le phisher, il existe plusieurs alternatives concernant le stockage des ressources du site web. Première solution : les stocker directement dans le kit de phishing, ce qui présente toutefois un inconvénient majeur, puisque ces ressources doivent être mises à jour régulièrement, au risque de créer un écart entre la page de phishing et la page authentique en termes d’aspect visuel et d’expérience utilisateur. Autre solution : référencer dans la page de phishing les liens vers les ressources stockées directement sur les domaines de la marque, ce qui garantit une expérience utilisateur authentique - les ressources s’actualisant automatiquement. Cette option présente en outre l’avantage d’exploiter la puissante bande-passante des domaines de la marque. Résultat : un temps de chargement rapide qu’un utilisateur serait en droit d’attendre d’un site web légitime. Un exemple est présenté en Figure 5, où les ressources (icônes et scripts) sont directement chargées à partir des domaines de la marque Chase.
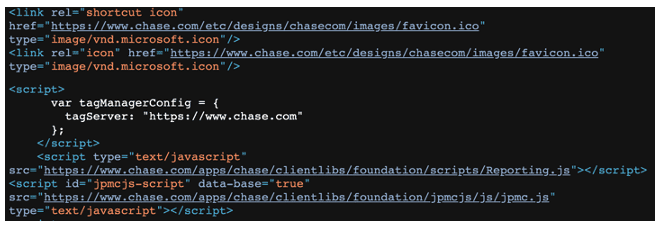
Figure 5 Phishing Chase récupérant des ressources sur les domaines de la marque
Entraînement et évaluation du modèle
Après cette brève introduction à l’extraction des caractéristiques, revenons au modèle d’Apprentissage Supervisé dans le cadre d’une tâche de classification. Au terme d’une évaluation de différents modèles sur notre jeu de données, nous avons opté pour une forêt d’arbres décisionnels (Random Forest). Cet algorithme de classification combine une multitude d‘arbres de décision pour générer une prédiction. Basée sur la méthode du bagging, contraction de « bootstrap aggregating », la classification Random Forest est connue pour produire une frontière de décision bien ajustée, permettant ainsi d’éviter les deux écueils habituels que sont le sous-apprentissage et le sur-apprentissage. La méthode se basant par ailleurs sur le tirage aléatoire des caractéristiques, elle est capable d’évaluer l’importance de chacune d’entre elles, et par là même de mettre de côté celles qui nuisent à la performance générale du modèle.
Les forêts d’arbres décisionnels produisent de bonnes performances sur la plupart des tâches d’Apprentissage Automatique (Machine Learning), ce qui fait que cet algorithme est très prisé des data scientists. Notre algorithme a été entraîné au moyen d’une méthode de validation croisée k-fold, et ses paramètres sont sélectionnés par la méthode grid search. Là encore, quelques explications s’imposent. Premièrement, les forêts d’arbres décisionnels présentent plusieurs paramètres dont le calibrage est nécessaire, comme le nombre ou la profondeur maximale des arbres, car il n’y a aucune garantie que les paramètres par défaut puissent produire de bons résultats.
En Apprentissage Automatique, ces paramètres sont appelés « hyperparamètres », et sont sélectionnés au moyen de stratégies diverses. L’une d’entre elles est la méthode grid search, qui consiste à lancer une recherche exhaustive des paramètres. Lors de l’étape suivante il est nécessaire de mettre en place une procédure d’évaluation de chaque sélection de paramètres. C’est là qu’intervient la méthode de validation croisée k-fold. D’abord, les données d’apprentissage sont réparties en k échantillons distincts. Le modèle est ensuite entraîné sur k-1 échantillons. L’échantillon restant, dit échantillon de validation, est ensuite utilisé pour évaluer le modèle. Le processus est répété k fois, avec un échantillon de validation différent pour chaque itération. La mesure de performance de la méthode de validation – et donc la performance de la sélection de paramètres - est égale à la performance moyenne du modèle produit à chaque itération.
La popularité de la méthode de validation croisée k-fold s’explique par sa capacité à éviter le sur-apprentissage grâce à un entrainement et à une évaluation du modèle sur des données différentes. Une fois les paramètres optimaux identifiés, le modèle final est généré à partir de ces paramètres et de l’intégralité du jeu de données d’apprentissage. Ses performances sont ensuite évaluées sur un jeu de données de test indépendant. Si les performances du modèle s’avèrent satisfaisantes, il pourra être déployé en production. Dans le cas contraire, il faudra l’améliorer, en commençant par examiner les faux positifs et faux négatifs et en affinant les caractéristiques.
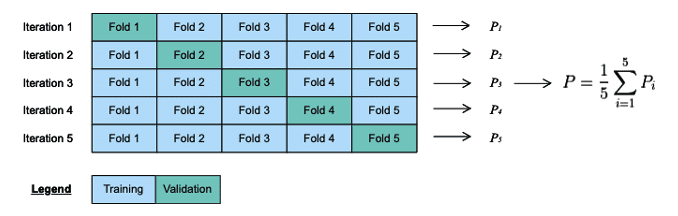
Figure 6 Exemple de validation croisée k-fold dans lequel k = 5
Dans notre prochain article, nous expliquerons comment un tokenizer BERT (tokenizer WordPiece) est appliqué à la paire URL/page web afin d’extraire un nouvel ensemble de caractéristiques. Nous aborderons également l’entraînement et l’utilisation d’un modèle d’Apprentissage Profond, qui nous permet de gagner en précision, tout en ayant un coût négligeable à l’exécution. Dans le quatrième et dernier article, nous aborderons le développement de notre technologie de détection de logos, qui est basée sur des modèles de détection d’objets VGG-16 et ResNet, et qui utilise une méthode originale de combinaison de prédictions afin d’améliorer la précision.


