本稿は、正確さと実行性能において強い制約がある中で、大規模なフィッシング攻撃を検出する際に直面した課題について解説する、4回シリーズの2回目になります。
シリーズ1回目では、メールストリーム内の疑わしいリンクを識別し、それに関連するWebページのコンテンツを取得する方法を説明しました。この2回目の記事では、教師あり学習技術に特にフォーカスしながら、Webページをリアルタイムで分析する方法を紹介します。3回目、4回目の記事では、ディープラーニングの使用について、より具体的にフォーカスします。
検出レイヤーを連携させることで、精度に関する課題を克服
対象となるURLのWebページを取得すると、URL/Webページのペアを分析して、それが悪意のあるものであるかどうかを判断します。スキャナーを開発する際に当社では2つの目標を定めます。まず、誤検出をゼロにすること、つまり正当なリンクを決してフィッシングとして分類しないことにコミットします。次に、重要な付加価値である、なりすましの多いブランドの特定を試みます。なお、顧客の観点からは決定がバイナリ、つまり「フィッシング」または「正当」のいずれかであるように見えるとしても、当社では「疑わしい」ステータスを内部で追加しています。この「疑わしい」ステータスによって、新たな脅威を捕え、誤検出ゼロの目標にコミットするのに役立つリアルタイムのテストを実行することができます。では、さまざまな検出レイヤー、
その長所と欠点について説明します。
1つ目の分析レイヤーであるスマートパターンは、YARAに似たテクノロジーです。各スマートパターンは、URL/Webページのペアに適用され、ブール式論理で表現された、ストリングと正規表現のセットで構成されます。フィッシング攻撃の大半は特定のブランドになりすますため、大抵の場合、スマートパターンはブランドに関連付けられます。ただし、ブランドによらず多くのフィッシングキットで使用されている特定の技術を検出した場合などの、例外的な状況もあります。
スマートパターンには、ブロッキングと非ブロッキングスマートパターンの2つのセットがあります。1つ目のセットは、ブロッキングスマートパターンと一致するあらゆるURL/Webページペアをブロックします。これは既知の脅威と既知の脅威の変種の検出において非常に効率的であることが実証されています。2つ目のセットは、新たな脅威を発見するために使用します。ただし、より複雑な技術(ディープラーニング、Computer Vision)を用いて自動化されているか、サイバーセキュリティアナリストが手動で行うかにかかわらず、URL/Webページペアをブロックするには確認が必要です。非ブロッキングスマートパターンが、いかなる誤検出も生じることなく新たなフィッシングを捕獲することが時間と共に証明されると、ブロッキングスマートパターンのセットに昇格します。そうでない場合は、望ましい精度に到達するまで、スマートパターンが微調整されるか、不良リードであった場合は単に破棄されます。
スマートパターンレイヤーが更新されるたびに、検証コーパスで評価されます。これにより、リグレッションがないことが確認され、誤検出ゼロのコミットメントを考慮する当社にとって特に重要となります。テストに合格したら、安全に展開することができます。Webのランドスケープの変化を追跡するために、検証コーパスも定期的に更新されます。スマートパターンレイヤーはシンプルで効率的ですが、限界があります。第一に、スマートパタンレイヤーは、意思決定のためのツリー構造と同様にバイナリー決定を行うため、決定のしきい値を微調整することができません。第二に、これは設計上、リアクティブな技術であるため、多数の未知の脅威を検出することができません。
2番目の分析レイヤーは、教師あり学習モデルに依存します。この場合、特徴ベクトルを構築するために、URL/Webページペアから数値的・カテゴリー的特徴が抽出されます。次に、特徴ベクトルが教師あり学習モデルに伝えられ、モデルがURL/Webページペアがフィッシングである確率を出力します。確率に応じて、URL/Webページペアがフィッシング(非常に高確率)、疑わしい(高確率)、または正当とみなされます。教師あり学習モデルはラベル付けされたトレーニングデータセット上で事前にトレーニングされており、そのパフォーマンスは、教師あり学習設定に従って、テストデータセット上で評価されます。
教師あり学習アルゴリズムを用いたフィッシング検出は新しいものではなく、数多くの文献が存在します。教師あり学習はスマートパターンレイヤーの限界に対処します。モデルが返す確率により、決定しきい値の微調整が可能になります。上手く調整された教師あり学習モデルは、一般化、つまり未知の脅威を検出する能力を備えています。ただし、スマートパターンレイヤーは、教師あり学習モデルの最大の課題である統計的異常値を検出するため、特に誤検出ゼロの制約を前提とした場合、どちらの手法も補完的なものであると言えます。
教師あり学習モデルで適切なバランスに到達
ここで、これまでに使用した、読者が知らない可能性のある概念を定義する必要があります。教師あり学習設定でモデルを構築するときは、2つの問題、オーバーフィットとアンダーフィットを避ける必要があります。オーバーフィットの場合は、モデルの決定境界がトレーニングデータにフィットし過ぎているため、結果として未知のデータを高精度で予測することができません。つまり、モデルがこれまでに見たことのないデータを「一般化」することができません。
オーバーフィットは通常、過度にトレーニングを実施したモデルで生じます。これは、トレーニングデータの主な統計的傾向を捕捉できないためです。エラーの観点からは、トレーニングデータに関しては、モデルのパフォーマンスが良すぎる一方、一般化できないため、未知のテストデータに対しては非常に弱くなります。アンダーフィットは、オーバーフィットの反対です。モデルが十分にトレーニングされておらず、決定境界がトレーニングデータと上手く合わないため、トレーニングデータと未知のテストデータの両方で、大きなエラーが生じます。
特徴選択やアンサンブル法(バギング、ブースティング)、k-fold交差検証など、オーバーフィットとアンダーフィットの適切なバランスを見つけるためのさまざまな手法が提案されています。決定境界が上手く調整されている場合でも、いくつかの統計的異常値、つまり教師あり学習モデルによって適切に捕捉されないデータが存在します。その場合は、スマートパターンテクノロジーなどの補完的技術を利用できるため、上手く調整された教師あり学習モデルを変更する必要はありません。
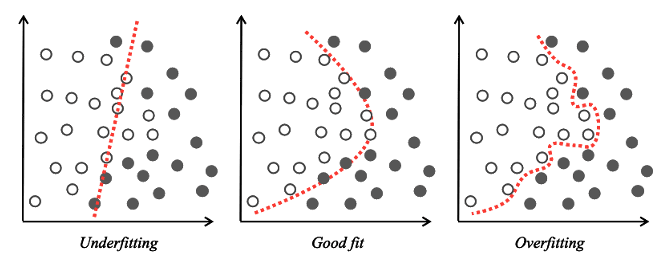
図 1 決定の境界-アンダーフィット、グッドフィット、オーバーフィット
特徴の抽出
教師あり学習分析レイヤーに関して、URL/Webページペアから合計52の特徴を抽出しました:URLから17件、HTMLドキュメントから35件。これらの特徴の選択の大半は、当社独自の経験と専門知識に基づくものですが、このトピックに関する研究文献は豊富で、当社の発見の大半を裏付ける、価値ある情報を提供してくれます。
52の特徴を抽出することは、これらすべての特徴を使用するという意味ではありません。実際、オーバーフィットを避けるために、最終モデルでは、統計的に見て最も関連性の高い特徴のみが維持されます。これらの特徴を詳しく見てみましょう。フィッシングWebサイトであることを示すものもあれば、良性のWebサイトに典型的な特徴もあります。
フィッシングの特徴の一つの例は、URLのサブドメイン部分にブランドのドメイン名が存在することです。ハッカーがサブドメイン部分にブランドのドメイン名を書く理由は、画面上のアドレスバーが切り捨てられてURLの左の部分しか表示されないため、スマートフォンユーザーが騙される可能性があるからです。
この場合、ユーザーは本物のWebサイトに接続していると思うかもしれません。図 2は、Sparkasse銀行を用いたこの手口の例を示しています。URLの左部分は、本物のhttps://sparkasse.deのWebページと見間違う可能性があります。この手口にはいくつかのバリエーションがあります。TLDが省略されたものもあれば、図 3に示すように、検出テクノロジーを回避するために誤字が挿入されたものもあります。誤字の場合は、amazon.co.jpのドメイン名との相関を見つけるために、厳密な文字列照合の代わりに、編集距離アルゴリズムを使用する必要があります。

図 2 SparkasseのフィッシングURL

図 3 Amazon JapanのフィッシングURL
その他の特徴は、良性のWebサイトにより多く見られます。このような例の一つは、HTTPS URLの存在です。これはユーザーとWebサイト間の通信が暗号化されていることを意味します。ただし、この特徴は、時間が経つにつれて関連性がより低くなる傾向があります。エンドユーザーには、Webサイトに機密情報を送信する前にブラウザのアドレスバーにHTTPSと鍵のアイコンが表示されているか確認するようアドバイスするのが一般的でしたが、いずれもWebサイトが信頼できる安全なものであることを保証することはできません。実際、2017年以降、HTTPSを使用するフィッシングサイトが劇的に増加しました。この場合、最近収集したデータを用いて、特徴が依然として統計的関連性があることを確認する必要があります。関連性がない場合は、最終モデルに残すべきではありません。
HTTPS URLの存在はブランドに依存しませんが、URLのサブドメイン部分にブランドのドメイン名があることは、SparkasseやAmazon Japanなど、そのブランドに固有のものです。当社の特許取得済みの教師あり学習アプローチの特長と新規性は、さらに高い精度を提供し、ブランドを検出するのに役立つ、ブランドに関連する特徴を抽出できることです。ブランドの検出は、フィッシング攻撃によるなりすましの対象となっているブランドの会社や組織に警告できるため、非常に役立ちます。これらのブランドは、顧客に警告し、不正なWebサイトの削除を要求するなど、必要な措置を講じることができます。IsItPhishing.AIで、Vadeからのブランドアラートにサインアップできます。
ブランドの検出は、さまざまな方法で行います。サブドメインに図 2や図3に示されるようなブランドへの言及が含まれている事実を利用することも可能です。これは良い手掛かりになりますが、ほとんどのフィッシングWebサイトには、URLにこのような明確な言及は含まれていません。Webページを調べて、ブランドを示すアーティファクト(通常はロゴ)を見つけることもできました。このアプローチは魅力的に見えるかもしれませんが、まずWebページの読み込みとレンダリングを行い、次に最後の記事でご紹介する技術、Computer Visionアルゴリズムを適用してこれらの視覚的アーティファクトを検出する必要があるため、リアルタイムで実行することはできません。
もう一つのアプローチは、Webページを見て、画像、アイコン、CSSファイル、スクリプトなど、Webページのリソースのうち、特定のブランドのドメインから取得したものが大きな割合を占めているかどうかを判断することです。実際、会社や組織は自身のWebサイトのリソースを、ブランドのメインドメインや、コンテンツデリバリーネットワーク(CDN)ドメインなど、評判の高い、数の限られたドメインに保存します。表図4にチェース銀行、Bank of America、PayPal、Sparkasse、Amazon JapanがWebリソースを保存するために使用しているドメインの例をリストアップします。

図 4 複数のブランドが使用するドメイン
ハッカーの観点からは、フィッシングWebページリソースの保存に関する複数のオプションがあります。まず、これらのリソースをフィッシングキットに直接保存できます。この手法の主な欠点は、リソースをアップデートする必要があることです。さもないと、時間が経つにつれて、フィッシングWebページの視覚的側面とユーザー体験が本物のWebページとは異なるものになってしまいます。もう一つの方法は、ブランドのドメインに直接保管されたリソースを、フィッシングWebページで参照することです。これは本物のWebページのルック&フィールを確保するのに役立ちます。ブランドのドメイン上の参照リソースがアップデートされた場合は、フィッシングWebサイトもアップデートされます。この手法には、ブランドのドメインの高性能帯域幅を利用できるメリットもあります。フィッシングWebサイトが本物のWebサイトと同じように素早く読み込まれます。このようなフィッシングページの一例を図5に示します。リソース(アイコン、スクリプト)がチェース銀行のドメインから直接読み込まれます。
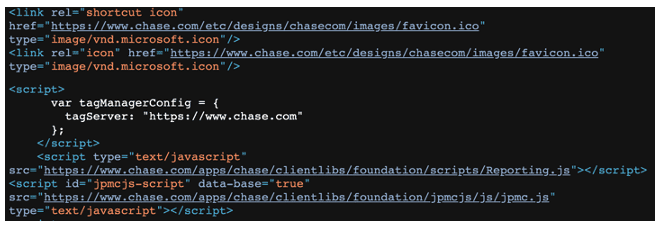
図 5 チェース銀行のドメインからリソースを取得する、チェース銀行のフィッシング
モデルのトレーニングと評価
特徴の抽出の概要をご覧いただいた後は、分類タスクで使用する教師あり学習モデルに戻りましょう。当社のデータセット上でさまざまなモデルを評価したあと、ランダムフォレストクラシファイアを使用することに決定しました。ランダムフォレストは、複数の意思決定ツリーを組み合わせて予測を出力する、人気のある分類アルゴリズムです。ランダムフォレストは、バギング法を基にしています。これは、アンダーフィットやオーバーフィットの通常の落とし穴を回避する、最適な決定境界を生成することで知られています。ランダムフォレストは、特徴の無作為性も基にしているため、各特徴の重要度を評価することができ、したがって、モデルのパフォーマンスを低下させる特徴を排除することになります。
ランダムフォレストは、大半のマシンラーニング分類タスクで上手く機能し、通常、多くのデータサイエンティストにとって第一の選択肢となっています。当社のクラシファイアは、k-fold交差検証法を用いてトレーニングされており、クラシファイアのパラメータはグリッドサーチ法を用いて選択されています。繰り返しますが、もう少し詳しく説明する必要があります。まず、ランダムフォレストクラシファイアには、意思決定ツリーの数や最大深度など、デフォルトのパラメータが良い結果をもたらす絶対的な保証がないため、調整が必要ないくつかのパラメータがあります。
クラシファイアのパラメータは、ハイパーパラメータとして知られています。これらのパラメータを選択するための複数の異なる戦略があり、その一つは、パラメータ空間をしらみ潰しに検索する、グリッドサーチ法です。次に、パラメータのそれぞれの選択を評価する手順が必要になり、ここでk-fold交差検証法が登場します。まず、トレーニングデータをk個の異なるフォールドに分割します。次に、k-1フォールドでモデルをトレーニングし、残りのフォールド(検証フォールド)を使用してモデルを評価します。各イテレーションで異なる検証フォールドを使用しながら、この手順をk回l繰り返します。k-fold検証のパフォーマンス測定(パラメータ選択のパフォーマンス)は、各イテレーションで生成されるモデルの平均パフォーマンスと等しくなります。
k-fold交差検証法は、異なるデータ上でモデルをトレーニングし、評価することでオーバーフィットを回避する、一般的な手法です。最適なパラメーターが見つかったら、これらのパラメータとトレーニングデータセット全体を使用して、最終モデルを作成します。その後、独立のテストデータセットで、そのパフォーマンスを評価します。モデルのパフォーマンスが満足できるものでなければ、モデルを改良する必要があります。誤検出(FP)とすり抜け(F
N)の学習と、特徴の微調整から始めるのが良い出発点となります。
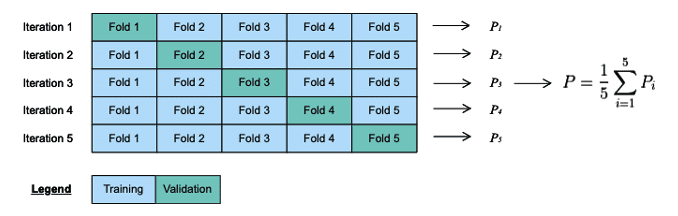
図 6 k=5のk-fold交差検証の例
次回は、URL/WebページペアにBERT WordPieceトークナイザーを適用して、新たな特徴のセットを抽出する方法をご紹介し、実行時に限られたコストで精度をさらに高めることができる、ディープラーニングモデルのトレーニングと使用についても説明します。最後の回では、VGG-16およびResNetオブジェクト検出モデルを特化させ、次にこれらの出力を組み合わせて精度を高めることにより、ロゴ検出技術をどのように開発したのかをご説明します。