

This article is the second of a series of four related to the challenges that we face to detect phishing attacks at scale with strong constraints on accuracy and runtime performance. In the first article, we described how we spot suspicious links within the email stream and then how we fetch the content of the associated webpages. In this second article, we will present how webpages are analyzed in real-time, with a specific focus on Supervised Learning techniques. In the third and fourth articles, we will focus more specifically on the use of Deep Learning.
Overcoming accuracy challenges by chaining detection layers
Once the webpage of the candidate URL has been fetched, it is possible to analyze the URL/webpage pair to determine whether it is malicious. When developing the scanner, we set two goals. First, commit to zero false positives; in other words: never classify a legitimate link as phishing. Second, try to identify the impersonated brand, as it is an important added value. Additionally, even if from a customer point of view the decision is binary, i.e., ‘phishing’ or ‘legitimate,’ we added internally an additional ‘suspicious’ status. This ‘suspicious’ status allows us to hunt new threats and perform real-time tests that help us to commit to the zero false positive goal. I will now describe the different detection layers and discuss their pros and cons.
The first analysis layer, Smart Pattern, is a YARA-like technology. Each smart pattern consists of a set of strings and regular expressions applied on the URL/webpage pair and articulated with a Boolean logic. In most cases, the smart pattern is associated to a brand, as most phishing attacks impersonate specific brands. There are, however, situations where this is not the case; for example, if we detect a specific technique used across many phishing kits, regardless of the brand.
There are two sets of smart patterns: blocking and non-blocking smart patterns. The first set blocks any URL/webpage pair that matches a blocking smart pattern, and it proves to be very efficient at identifying known threats and variants of known threats. The second set is used to discover new threats. Confirmation, however, is necessary to block a URL/webpage pair, whether it is automated using more complex technologies (Deep Learning, Computer Vision) or done manually by a cybersecurity analyst. If a non-blocking smart pattern proves over time to catch new phishing without provoking any false positive, then it will be promoted to the set of blocking smart patterns. Otherwise, the smart pattern will be fine-tuned until it reaches the expected accuracy, or it will be simply discarded if it was a bad lead.
Each time the Smart Pattern layer is updated, it is evaluated on a validation corpus. This allows us to ensure no regression, which is particularly important considering our zero false positive commitment. If it passes the test, then it can be deployed safely. The validation corpus is also updated regularly to follow the evolution of the web landscape. The Smart Pattern layer is simple and efficient, but it has limitations. First, it gives a binary decision, as it is similar to a decision tree, which prevents fine-tuning of a decision threshold. Second, it fails to detect many unknown threats, as it is by design a reactive technique.
The second analysis layer relies on a Supervised Learning model. In this case, numerical and categorical features are extracted from the URL/webpage pair to build a feature vector, and the feature vector is then passed to a Supervised Learning model that outputs the probability that the URL/webpage pair is phishing. Depending on the probability, the URL/webpage pair will be considered as phishing (very high probability), suspicious (high probability), or legitimate. The Supervised Learning model has been previously trained on a labeled training dataset and its performance evaluated on a test dataset—as is customary in a Supervised Learning setting.
The use of Supervised Learning algorithms to detect phishing is not new and well documented. Supervised Learning addresses the limitations of the Smart Pattern layer: the probability returned by the model allows fine-tuning of the decision threshold, and a well-tuned Supervised Learning model has the ability to generalize; in other words, to detect unknown threats. However, both techniques are complementary, as the Smart Pattern layer can detect statistical outliers, which is the biggest challenge for a Supervised Learning model, especially given the zero false positive constraint.
Related article: Phishers' Favorites H1 2022: Top 25 Most Impersonated Brands in Phishing
Achieving a fine balance with Supervised Learning models
At this point, it is necessary to define some notions that have been used and may be unknown to the reader. While building a model in a Supervised Learning setting, it is necessary to avoid two issues: overfitting and underfitting. In the case of overfitting, the decision boundary of the model fits the training data too closely, and as a consequence fails to predict with accuracy unknown data —the model fails to ‘generalize’ on previously unseen data.
Overfitting generally results from the model being overtrained because it fails to capture the dominant statistical trend of the training data. From an error point of view, the model performs too well on the training data and very poorly on unknown test data, as it fails to generalize. Underfitting is the opposite of overfitting: the model has not been trained enough, and the decision boundary poorly fits the training data, resulting in high error on both the training data and unknown test data.
Many techniques have been proposed to find the right balance between overfitting and underfitting, such as feature selection, ensemble methods (bagging, boosting), and k-fold cross validation. Even if the decision boundary is well tuned, there will still be some statistical outliers—data that will not be captured correctly by the Supervised Learning model. In this case, a complementary technique such as the Smart Pattern technology can be used, without the need to alter the well-tuned Supervised Learning model.
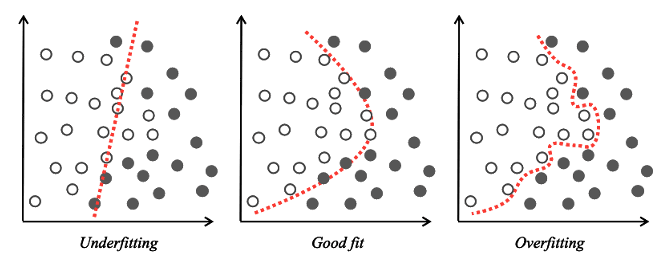
Figure 1 Decision boundary –Underfitting, good fit and overfitting
Feature extraction
Regarding our Supervised Learning analysis layer, we extract a total of 52 features from the URL/webpage pair: 17 from the URL and 35 from the HTML document. The choice of these features has been mostly driven by our own experience and expertise, although the documentation on this topic in the research literature is extensive and provides valuable information that corroborates most of our findings.
That we extract 52 features doesn’t mean that all of these features will be used. In fact, to avoid overfitting, only the most relevant features from a statistical point of view will be kept in the final model. Let’s have a closer look at these features. Some are indicative of a phishing website, while others are typical of a benign one.
An example of a phishing feature is the presence of a brand domain name in the subdomain part of the URL. The reason for the phisher to write the brand domain name in the subdomain part is that users of a smartphone may be tricked, as the address bar on the screen may be truncated and thus only show the left part of the URL.
In this case, the user may think he is connecting to the genuine website. Figure 2 shows an example of this trick with the Sparkasse bank, where the left part of the URL may be confused with the genuine https://sparkasse.de webpage. The are several variants of this trick. In some cases, the TLD is omitted, or typos are inserted to bypass detection technologies, as shown in Figure 3. In the case of typos, it is necessary to use an edit distance algorithm instead of strict string matching to find the correlation with amazon.co.jp domain name.

Figure 2 Sparkasse phishing URL

Figure 3 Amazon Japan phishing URL
Other features are more prevalent for benign websites. An example of such a feature is the presence of an HTTPS URL, which means that the communication between the user and the website is encrypted. This feature tends, however, to become less relevant over time. While it was generally advised to the end user to look for the presence of HTTPS and a lock icon in the address bar of their browser before submitting any sensitive information to a website, neither ensures that a website is trustworthy or secure. In fact, there was a dramatic increase in phishing sites using HTTPs that started in 2017. In this case, it is necessary to ensure that the feature is still statistically relevant to the recently collected data, and if it is not, it should not be kept in the final model.
The presence of an HTTPS URL is brand agnostic, while the presence of a brand domain name in the subdomain part of URL is specific to the brand, e.g., Sparkasse or Amazon Japan. The specificity and novelty of our patented Supervised Learning approach are that we extract features related to brands, which provides an extra gain in accuracy, and also allows us to detect the brand. Detecting the brand is very useful as we can alert companies and organizations whose brands are impersonated in phishing attacks. Those brands can then take necessary measures, such as warn their customers and request a takedown of the fraudulent website. You can sign up for brand alerts from Vade at IsItPhishing.AI.
The detection of the brand may be achieved in different ways. We could use the fact that the subdomain contains a reference to the brand such as presented in Figure 2 and Figure 3. This is a good clue, but most phishing websites do not contain such an obvious reference in the URL. We could also look at the webpage and find visual artifacts that are indicative of a brand, typically a logo. As tempting as it may seem, this approach cannot be done in real-time, as it requires first loading and rendering the webpage, and then applying Computer Vision algorithms to detect these visual artifacts, a technique that will be presented in our last article.
Another approach is to look at the webpage and determine if a significant proportion of resources of the webpage—images, icons, CSS files, and scripts—is fetched from a specific brand’s domains. Indeed, companies and organizations store the resources of their website on a limited number of high reputation domains, such as the brand’s main domain or content delivery network (CDN) domains. Table Figure 4 lists examples of the domains used by Chase, Bank of America, PayPal, Sparkasse, and Amazon Japan to store web resources.

Figure 4 Domains used by several brands
From a phisher’s perspective, there are several options regarding the storage of phishing webpage resources. First, these resources can be stored directly in the phishing kit. The main drawback of this method is that resources need to be up to date, otherwise the visual aspect and user experience of the phishing webpage will diverge over time compared to the genuine webpage.
An alternative is to reference in the phishing webpage the resources stored directly on the brand’s domains, which helps to ensure the look and feel of the genuine website; if a resource referenced on the brand’s domains is updated, then the phishing website will be updated as well. This method also offers the advantage of using the high-performance bandwidth of the brand’s domains—the phishing website will load quickly, as would be the case for the genuine website. An example of such a phishing page is presented in Figure 5, where resources—icons and scripts—are loaded directly from Chase’s domains.
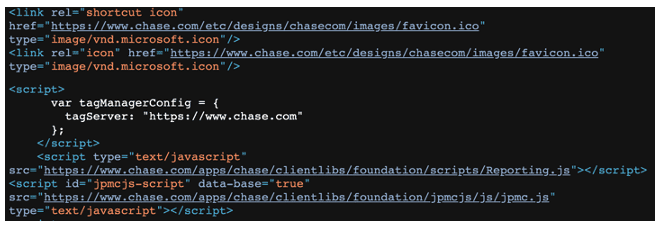
Figure 5 Chase phishing that fetches resources from Chase’s domains
Training and evaluation of the model
After a first glimpse at the extraction of features, let’s go back to the Supervised Learning model used for the classification task. We have decided to use a Random Forest classifier after evaluating different models on our dataset. Random Forest is a popular classification algorithm that combines several decision trees to output a prediction. As Random Forest is based on the bagging method, it is known to produce an optimum decision boundary, avoiding the usual pitfalls of underfitting and overfitting. As Random Forest is also based on feature randomness, it has the ability to evaluate the importance of each feature and thus will drop features that decrease the model performance.
Random Forest performs well on most Machine Learning classification tasks—it is usually the first choice for many data scientists. Our classifier has been trained using a k-fold cross validation method where the parameters of the classifier have been selected using a grid search method. Once again, it is necessary to provide a little bit more explanation. First, the Random Forest classifier has several parameters that need to be tuned, such as the number of decision trees or the maximal depth of a decision tree, as there is no absolute guarantee that the default parameters will give good results.
The parameters of a classifier are also known as hyperparameters. There are different strategies to select these parameters, and one of them is the grid search method which performs an exhaustive search over the parameters’ space. Then, it is necessary to have a procedure to evaluate each selection of parameters, and that’s where the k-fold cross validation method comes into place.
First, the training data is split into k different folds. Then the model is trained on k-1 folds, and the remaining fold—the validation fold—is used to evaluate the model. The procedure is repeated k times, with a different validation fold at each iteration. The performance measure of the k-fold validation—the performance of the selection of parameters—is equal to the average performance of the model produced at each iteration.
The k-fold cross validation method is a popular procedure that avoids overfitting since the model is trained and evaluated on different data. After optimal parameters are found, the final model is produced with these parameters and the whole training dataset. Its performance can then be evaluated on the independent test dataset. If the model performance is satisfying, it can be deployed in production; otherwise, it is necessary to improve the model–studying the false positive and false negative, and tuning the features is a good starting point.
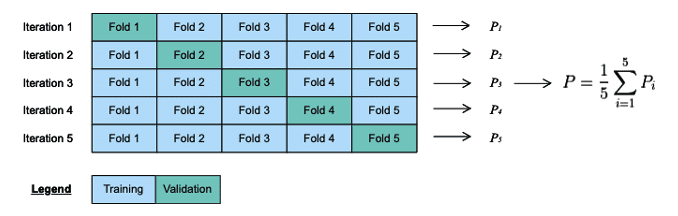
Figure 6 Example of k-fold cross validation with k=5
In the next article, we will present how a BERT WordPiece tokenizer is applied to the URL/webpage pair to extract a new set of features, and discuss also the training and use of a Deep Learning model, allowing an extra gain in accuracy for a limited cost at runtime. In the fourth and last article, we will explain how we have developed a logo detection technology, by specializing VGG-16 and ResNet object detection models and then combining their outputs for improved precision.



