

This article is the third of a series of four related to the challenges that we face to detect phishing at scale with strong constraints on accuracy and runtime performance. In the first article, we described how we spot a suspicious link within the email stream and then how we fetch the content of the associated webpage to form a URL/webpage pair. In the second article, we presented how the URL/webpage pair is analyzed and evaluated by different detection layers. In this context, we discussed feature engineering, model fitting, and training and evaluation of a Random Forest classifier in a Supervised Learning setting.
In this article, we will first present the evolution of Machine Learning techniques over time, from traditional algorithms that rely most on domain knowledge to extract features, to modern techniques combining Natural Language Processing and Deep Learning models. We will then introduce hybrid models that combine the best of both approaches, and then we will present the architecture of our hybrid model. Finally, we will show how this model allows us to get an extra gain in accuracy.
Traditional Machine Learning algorithms
Traditional or conventional Machine Learning algorithms refer to models that have been widely used for the task of classification and that are still very popular today. We can mention, for example, Random Forest, Support Vector Machine (SVM), and Logistic Regression. These models have important qualities. First, they do not require a large amount of training data and perform reasonably well with a small training dataset. The consequences are a low dependency on data availability and reduced labeling costs in the context of Supervised Learning. Second, these models are explainable, which means that a human can understand a model’s prediction.
The main drawback of these models, however, is that they are not able to process raw data, and they require expert knowledge and careful engineering to transform raw data into a relevant and suitable numerical representation. Indeed, poorly chosen features will lead to a poor performing model, regardless of the sophistication of the algorithms and the size of the dataset used for training and evaluation.
In the previous article, we mentioned that a total of 52 heterogenous features were extracted from the URL/webpage pair and the choice of these features was driven by our experience and expertise. By creating these features manually, we have essentially transferred our expert knowledge; in other words, we have translated the clues that we use in our decisional mental process for the task of phishing detection into a programmatic form. Manual feature engineering is highly recommended when done by an expert, as it allows you to create a small set of features that is highly relevant for the classification task.
It is, however, possible to improve the expert feature set by discovering other features automatically. There may be some features that the expert will not have noticed because the signal is too weak for a human, while a computer program may discover the statistical correlations from the raw data. Furthermore, depending on the classification task, one-shot manual feature engineering task may not be enough. This is the case in the context of cybersecurity, where the threat landscape, which is adversarial by nature, is dynamic, and thus feature engineering needs to be performed periodically as the attackers’ techniques evolve over time. Manual feature engineering is costly and time consuming, and automated feature engineering helps to fill the gaps.
A well-known and conventional method to extract features from text is the 'Bag of Words' (BoW) model, which builds a vocabulary from the words extracted from a collection of text documents, and then models a text document by evaluating the importance of each word within the document. There are many variants of this simple and intuitive model. Word importance may be calculated by counting words, computing the word frequency or the Term Frequency-Inverse Document Frequency (TF-IDF). As the size of the vocabulary grows quickly with the number of documents, it is customary to perform pre-processing on the text, such as ignoring case and punctuation, removing stop words, reducing words to their stem, or alternatively to their lemma. The size of the vocabulary may also be fixed so that only the most frequent words are kept.
Although intuitive and versatile, the BoW model suffers from significant shortcomings. First, as the order of words is discarded, some of the context and semantic content is lost. Second, it produces sparse numeric representations of text documents, which is not suitable from a computational point of view. Indeed, automated feature engineering tends to produce sparse high-dimensional data, for which traditional Machine Learning algorithms do not perform well. With the recent breakthroughs in Deep Learning and Natural Language Processing, there was a natural evolution of the cybersecurity community to explore these techniques to improve the detection of cyberattacks.
Natural Language Processing- and Deep Learning-based methods
Deep Learning is a subset of Representation Learning, where the model can discover automatically from the raw data the representations, or features, needed for the classification task. Deep Learning models are composed of multiple processing layers of interconnected nodes, to extract an increasingly abstract representation of the raw data. For instance, in the case where the raw input data is an image, a Deep Learning model would typically extract in the first layer of representation edges from the image, the second layer of representation would detect small motifs resulting from particular arrangements of these edges, and the third layer would extract combinations of these motifs, thus building an increasingly abstract representation of the image. This ability to discover relevant representations is essential and theoretically eliminates the need for a domain expert to craft relevant features.
Another advantage of Deep Learning is that the model accuracy can be improved by training on larger datasets, while traditional Machine Learning algorithms tend to reach a performance plateau quite quickly. Deep learning has limitations, however. First, Deep Learning models perform poorly on small training datasets and are outperformed by traditional Machine Learning algorithms in this setting. This dependence on the amount of data can be costly if the training data needs to be labeled. Second, Deep Learning models are difficult to interpret. Finally, tuning Deep Learning models can be complex and requires significant expertise to achieve good results.
In the context of phishing detection, we first need to transform the URL/webpage pair into a form that can be processed by the Deep Learning model. As the URL/webpage pair are intrinsically made up of text elements, it is natural to use Natural Language Processing techniques. The BoW model introduced previously is a first simple approach but with important limitations. More sophisticated models have been proposed. First, in ‘Word Embedding’ models, such as Word2vec, each word is represented by a single vector of real valued features and words that have a similar meaning are close in the feature space. Figure 1 illustrates how word vectors are represented and related to each other in the feature space, after a projection to a two-dimensional space with t-SNE algorithm.
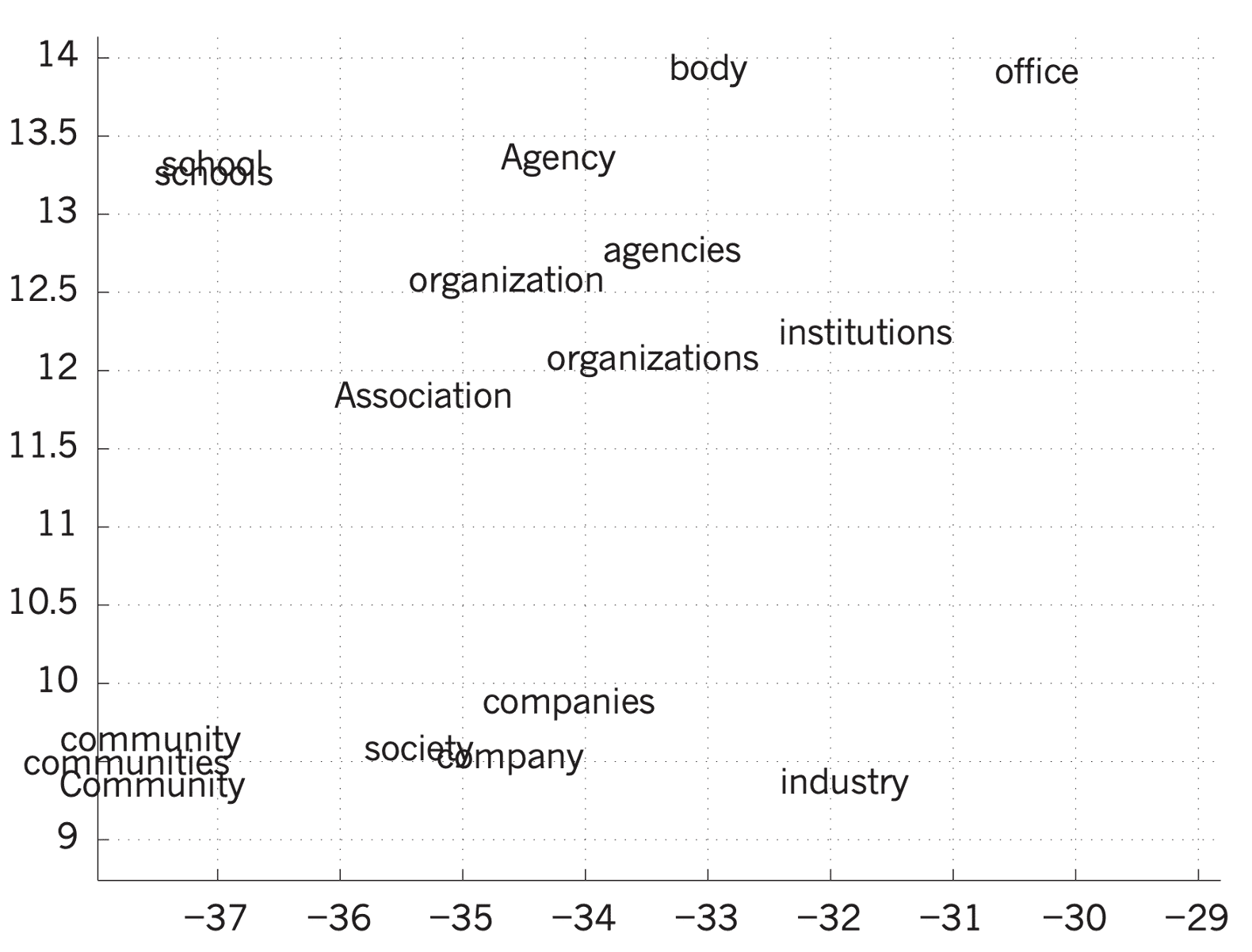 Figure 1 Word embedding: Semantically related words are close to each other in the feature space (Source: ‘Deep Learning’)
Figure 1 Word embedding: Semantically related words are close to each other in the feature space (Source: ‘Deep Learning’)
One of the key benefits of ‘Word Embedding’ based techniques is that they can produce a dense and low-dimensional vector, which makes computation very efficient, especially in the context of Deep Learning. The main limitation of this approach is that, because a word is represented by a single vector, it is not possible to correctly handle polysemous words, i.e., words that have a different meaning depending on the context. The ‘Word Embedding’ model is known as ‘context-free,’ as the context of a given word is not considered.
Models have been developed to overcome the polysemy disambiguation problem. These models are known as ‘contextualized’ and constitute state-of-the-art language models. An example of such model is BERT, in which the word vector assigned to a word is context dependent. While language models such as Word2vec and BERT can be trained from scratch, it is customary to use a pre-trained model and then eventually fine-tune the model on the specific task with additional data. The use of a pretrained model is highly recommended as it dramatically reduces the training cost. An example of pretrained BERT model is the BERT case-sensitive base model for English language introduced by Google in the seminal publication, ‘BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding’. A wide variety of pretrained language models are available, covering different languages and various tasks.
Hybrid models
To combine the best of both approaches, hybrid models have been introduced, such as those proposed by Ozcan et al. and Afzal et al., which yield a better accuracy than non-hybrid models. The key idea behind a hybrid model is to use different features, such as features handcrafted by an expert as well as features extracted with Natural Language Processing techniques, and then combine these features within a Deep Learning model. It is a misconception to assume that all the expert knowledge of a given domain can be discovered automatically. This is especially true in a highly technical domain such as cybersecurity, where complex features can be crafted by combining different kinds of data, such as for host-based features that can be derived from the URL by using DNS records, WHOIS information, or geolocation.
When we developed our hybrid model, we had the idea to reuse the URL/webpage features that we have already computed for our Random Forest classifier, and then compute another set of features by applying Natural Language Processing techniques on the URL. By then applying Deep Learning on this combined set of features, we were hoping that new patterns could be discovered, and that the hybrid model would yield superior accuracy to our Random Forest classifier. Thus, by chaining the Random Forest classifier and the hybrid model, where the hybrid model is used to confirm decisions of the former when the confidence is not high enough, we could improve the global accuracy of the phishing detection technology. Figure 2 presents the architecture of our hybrid model.
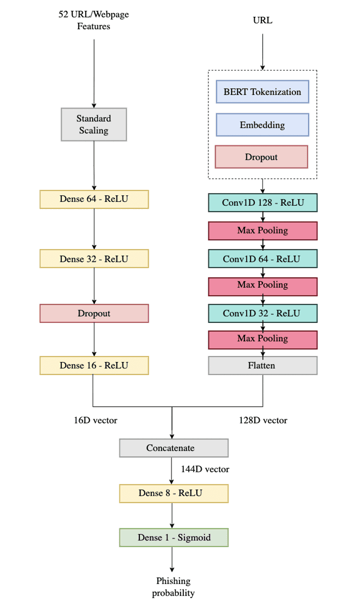 Figure 2 Architecture of hybrid model
Figure 2 Architecture of hybrid model
The hybrid model consists of two distinct parts. On the left-hand side, the heterogenous set of 52 manually engineered features extracted from the URL/webpage pair and used by the Random Forest classifier is transformed by a succession of different processing layers into a 16-dimensional vector. The processing pipeline includes a dropout layer, a regularization technique that helps to reduce overfitting and improve the generalization of the model, a topic that was discussed in our previous article. The key idea of dropout is to drop randomly and temporarily units, along with their incoming and outgoing connections, from the Neural Network. Figure 3 presents an example of dropout on a 2 hidden layers Neural Network.
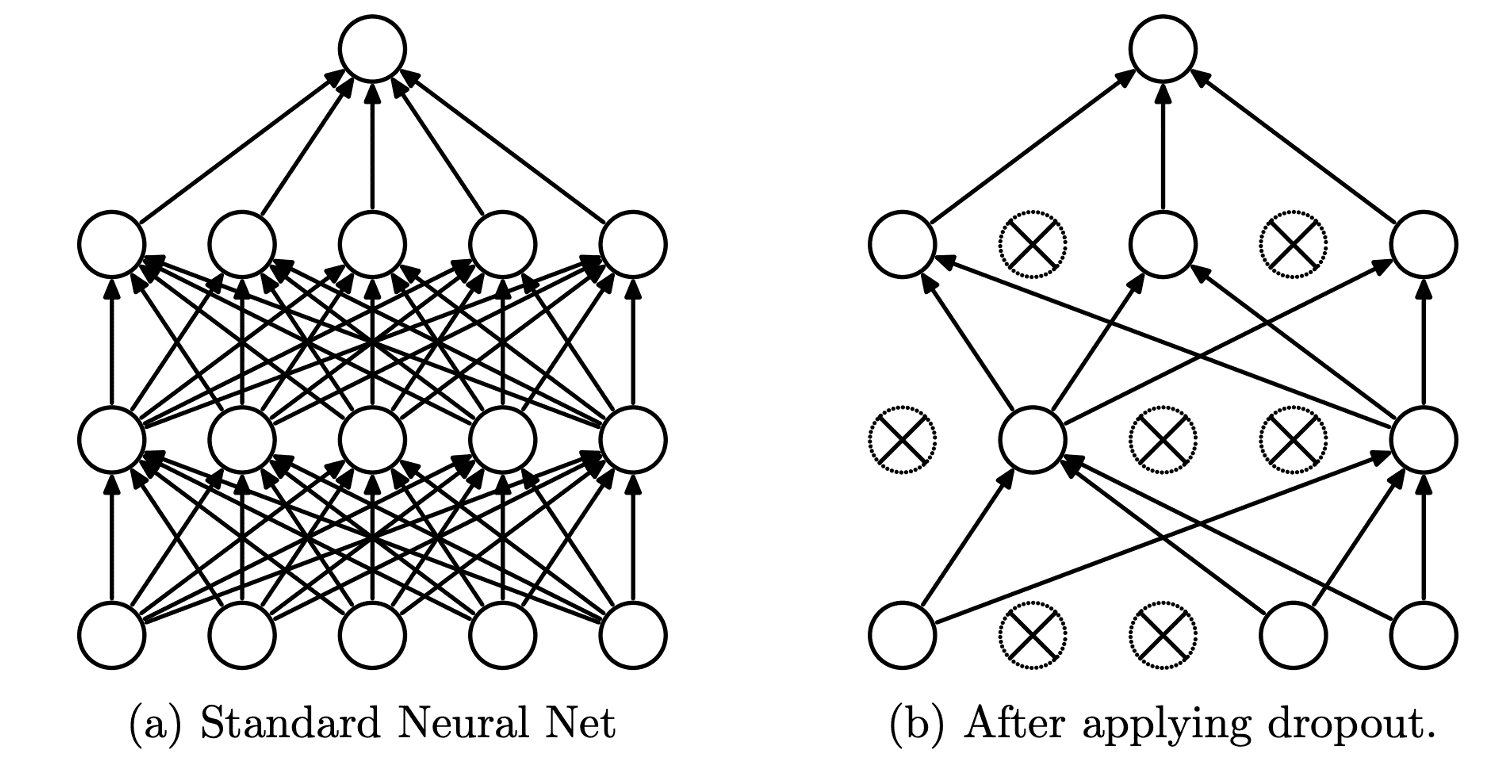
Figure 3 Use of dropout on a 2 hidden layers Neural Network (Source: 'Dropout: A Simple Way to Prevent Neural Networks from Overfitting')
On the right-hand side, the URL is processed by numerous layers to produce a 128-dimensional vector. First, based on the recent advances in Natural Language Processing, the URL is transformed with a BERT WordPiece tokenizer into a sequence of sub-words from a finite vocabulary size of 30522 sub-words. As the BERT WordPiece tokenizer produces a sparse vector of vocabulary indices, it is then transformed into a dense vector with an embedding layer, followed by a dropout layer. The next layers are then typical of a Convolutional Neural Network (CNN or ConvNet) architecture, with a succession of convolutional layers and pooling layers, to build progressively an abstract representation of the data. Figure 4 presents a typical ConvNet architecture for image recognition , where the input are the 3 RGB color channels of the image, and the output is the probability associated to each class.
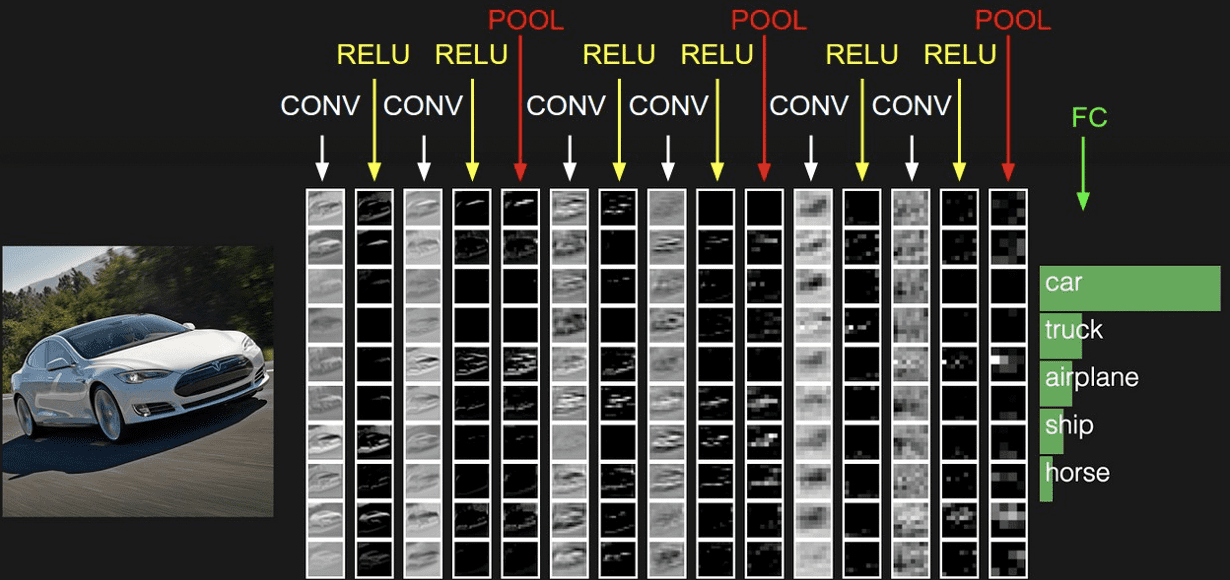 Figure 4 A typical ConvNet architecture for image recognition (Source: CS231n Convolutional Neural Networks for Visual Recognition)
Figure 4 A typical ConvNet architecture for image recognition (Source: CS231n Convolutional Neural Networks for Visual Recognition)
The role of the convolutional layer is to extract local motifs from the data, where the data can take the form of a n-dimensional array. For instance, signals and sequences, including text, can be represented by a 1-dimensional (1D) array, while 2-dimensional (2D) and 3-dimensional (3D) arrays are used respectively for images and videos. In Figure 4, as an image is 2-dimensional, 2D convolutional layers are applied. In our case, as we process text, we use 1D convolutional layers with a convolution window, or kernel, of size 6. The pooling layer is applied after the convolutional layer, and its purpose is to downsample the representation.
Advantages of pooling are twofold. First, it summarizes the features present in a local region of the features map, which makes the model more resilient to small local variations. Second, it reduces the numbers of parameters and thus the amount of computation required. Figure 5 presents an example of 2D max pooling for image recognition, where only the maximal value of each local region is kept. Again, as we process text, we use 1D pooling layers.
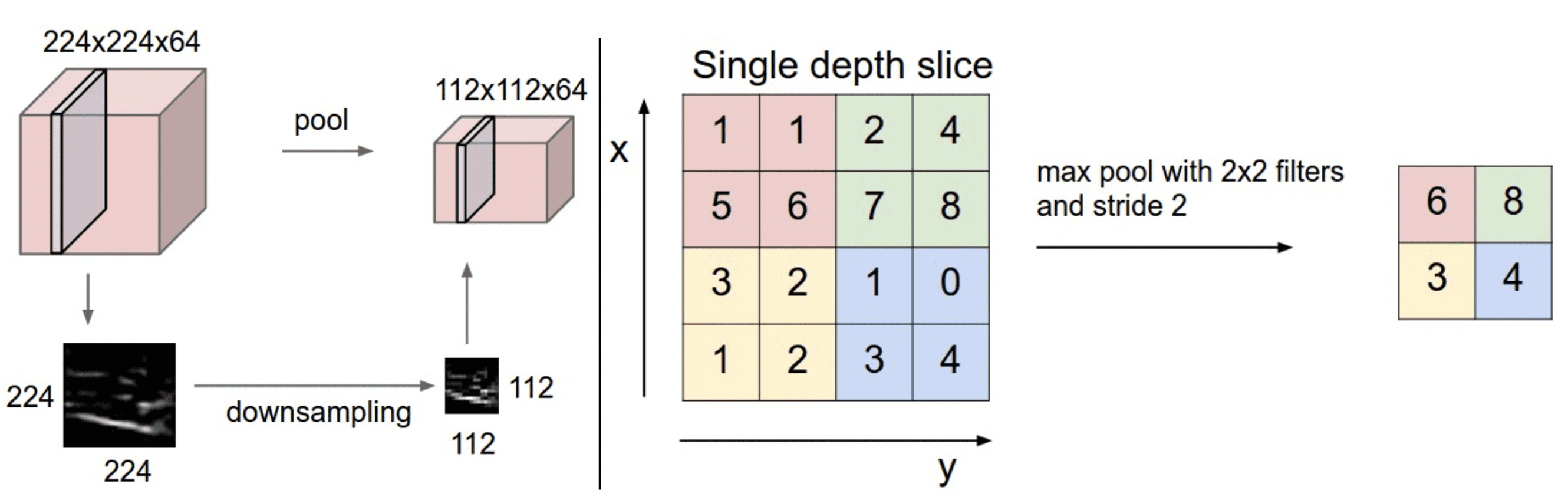 Figure 5 2D max pooling (Source: CS231n Convolutional Neural Networks for Visual Recognition)
Figure 5 2D max pooling (Source: CS231n Convolutional Neural Networks for Visual Recognition)
After several rounds of convolution and pooling, the representation of the URL is reduced to a 128-dimensional vector. The two vectors are then merged into a 144-dimensional vector which is inputted into a fully connected layer, followed by a final Sigmoid function. The final output is the probability of the considered URL to be malicious.
Impact
Our URL scanner combines several detection technologies. The first layer—Smart Pattern—detects known threats and variants of known threats. The second layer is based on a Random Forest model that can detect many unknown threats, thanks to its generalization ability. The third layer is the hybrid model presented previously, which can detect even more complex threats, as Deep Learning can find correlations that traditional Machine Learning algorithms cannot. Finally, the last line of defense are the SOC analysts that can block the most complex threats and update the different layers to adapt to the evolution of the threat landscape.
The impact of the hybrid model on the workload of the SOC analysts is significant. While analysts must supervise more than 250,000 suspicious URLs per year, the hybrid model has reduced the quantity of suspicious URLs by approximately 30%. Furthermore, the hybrid model makes a decision in 15 milliseconds on average, while it takes more time for an analyst to decide if a URL should be blocked. As timing is key in cybersecurity, the hybrid model helps to block some of the most sophisticated attacks almost immediately. In the next and last article, we will continue to explore Deep Learning models. In particular, we will discuss how we have specialized VGG-16 and ResNet models for the specific task of detecting logos in an image.


